ReadPaper Blog
Z-Reward: Internalizing Reasoning into Score Distributions for Visual Reward Modeling
Z-Reward addresses visual reward modeling for text-to-image post-training, where human preferences are subjective and are better represented as score distributions than as single scalar rewards. The paper proposes a teacher-student framework in which a large reasoning VLM learns rubric-aligned score distributions with Group-wise Direct Score Optimization, while a compact VLM internalizes those judgments through Reasoning-Internalized Score Distillation for efficient and differentiable deployment.
Source: Z-Reward: Internalizing Reasoning into Score Distributions for Visual Reward Modeling

Why one score feels too flat
The paper argues that reward models for text-to-image generation should not reduce visual preference to a single deterministic score, because judgments about aesthetics, realism, physical plausibility, and text-image alignment vary across annotators and often contain meaningful uncertainty. Existing scalar, score-token, and pairwise reward models are criticized for over-compressing fine-grained differences, such as two images that both receive a coarse score of 4 while differing in how close they are to adjacent rubric boundaries. Z-Reward instead treats preference as a distribution over rubric scores, allowing probability mass to reflect ambiguity among neighboring quality levels. The paper grounds this motivation in a five-level rubric and a nine-level half-point annotation scale from 1.0 to 5.0, designed to capture subtle differences that integer bins can hide. This framing matters because post-training, model selection, and reward-guided optimization depend on signals that preserve uncertainty rather than discard it.
The two-sided problem
The paper identifies a central tradeoff in visual reward modeling: stronger judgments often require reasoning, but production rewards must be fast, stable, and usable as optimization signals. Reasoning-based generative reward models can use visual evidence, world knowledge, and explicit rationales to make better assessments, yet their long textual outputs are expensive at inference time and awkward for direct gradient-based optimization. Efficient scalar or pairwise models are easier to deploy but lose distributional uncertainty and fine-grained score gaps. Z-Reward’s thesis is to decouple judgment quality from reward efficiency, so that reasoning can improve the learning target without forcing deployment-time reasoning chains. This distinction lets the paper define a reward model as something that should reproduce how a reasoning system judges, not necessarily how that system verbalizes its reasoning.
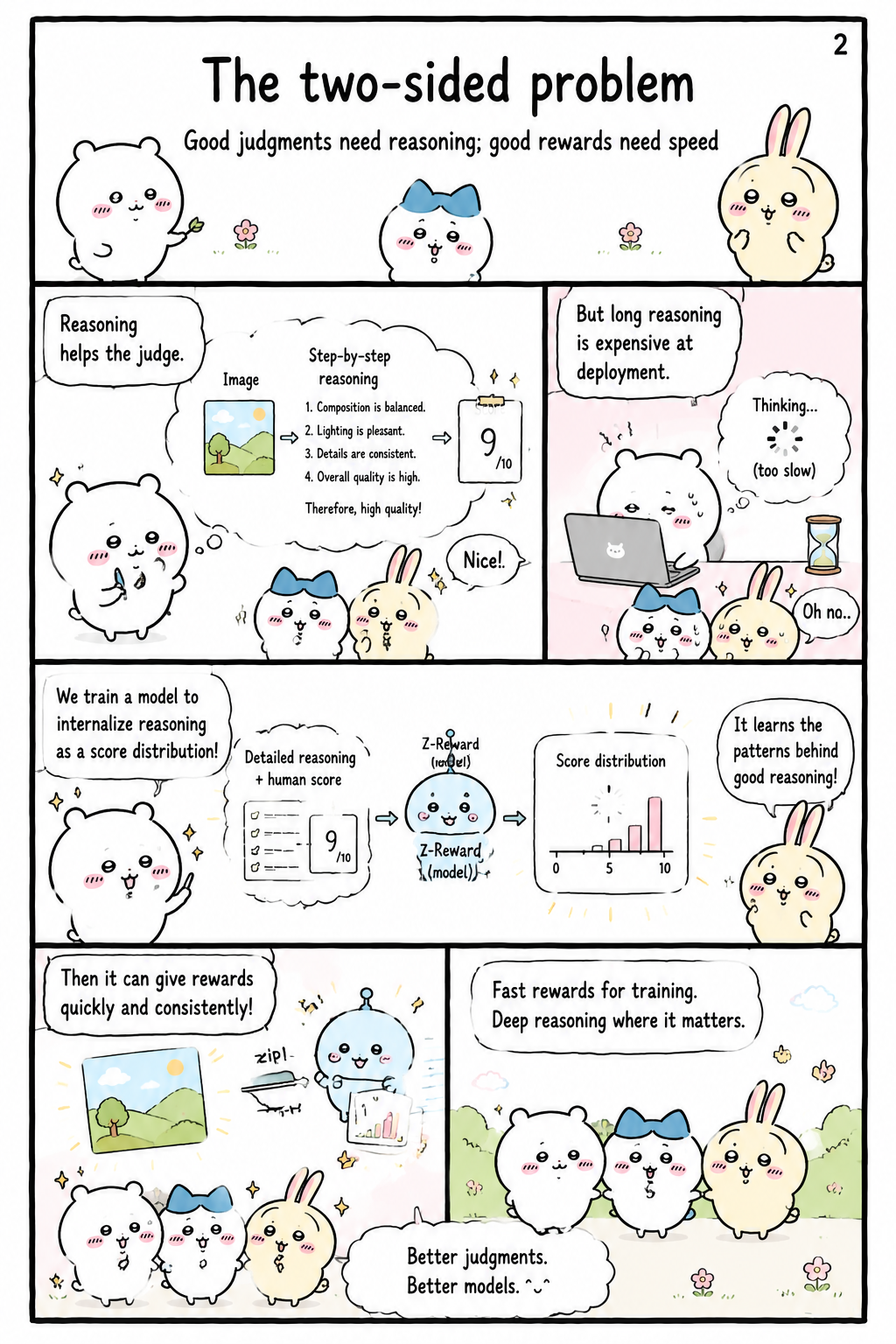
Z-Reward’s trick
Z-Reward implements this decoupling with a teacher-student architecture built around score distributions rather than exposed rationales. The teacher is a large vision-language model that uses reasoning to infer calibrated, rubric-aligned score distributions for a text-image pair, decomposing visual evidence across criteria such as alignment, realism, aesthetics, and physical plausibility. The student is a compact VLM trained to output the teacher’s reasoning-conditioned score distribution directly, without generating explicit reasoning tokens at inference time. The paper calls this transfer Reasoning-Internalized Score Distillation, emphasizing that the student internalizes the effect of reasoning on the distribution rather than imitating a chain of thought. This design supports efficient scoring, gradient backpropagation, and large-scale use in text-to-image post-training while retaining much of the teacher’s judgment quality.

How the teacher learns
The teacher is trained with Group-wise Direct Score Optimization, a method that combines policy-gradient rewards derived from distribution expectations with direct supervision over pointwise score distributions and pairwise score gaps. The paper’s annotation setup uses rubric-guided human scores across production-critical dimensions, with annotators assigning pointwise scores, adjusting same-prompt candidates by half-point differences when distinguishable, and passing results through quality-control review. Because repeated annotations for every training sample would be costly, GDSO learns latent reasoning-conditioned score distributions from scalable rubric-based supervision rather than requiring dense human distributions everywhere. The paper also highlights context mismatches that motivate this method: the full annotation document would exceed practical VLM context limits, and annotators can compare candidates under the same prompt while a deployable pointwise reward model usually sees only one text-image pair. GDSO is presented as the mechanism that lets the large teacher absorb rubric structure and comparative evidence into calibrated distributional judgments.

What the paper shows
The paper reports that the 27B GDSO teacher reaches 89.6% human preference accuracy on an internally annotated evaluation set, outperforming SFT, RewardDance, and GRPO baselines. It further reports that the 9B RISD student reaches 88.6% human preference accuracy, surpassing the OPD baseline while closely matching the larger teacher despite omitting explicit reasoning chains at inference time. These results support the claim that reasoning-enhanced reward judgments can be compressed into a smaller model as score distributions without losing most of the teacher’s preference accuracy. The paper also evaluates Z-Reward as a differentiable reward signal for text-to-image optimization and reports a 41.3% net human-preference improvement over the SFT baseline. The implication is that distributional visual rewards can serve both as better evaluators of subjective image quality and as practical optimization signals for improving generative models.
