ReadPaper Blog
Where Do Deep-Research Agents Go Wrong? Span-Level Error Localization in Agent Trajectories
This paper studies how to locate the specific harmful steps inside long deep-research agent trajectories, rather than judging only whether the final answer is correct. It introduces TELBENCH, a benchmark built from real agent logs segmented into semantic spans, and proposes DRIFT, a claim-centric auditing framework that traces unsupported or conflicting claims through the trajectory. The result matters because deep-research agents can appear reliable at the output level while depending on earlier commitments that were never properly supported.
Source: Where Do Deep-Research Agents Go Wrong? Span-Level Error Localization in Agent Trajectories

When the final answer looks fine...
The paper argues that deep-research agents should be evaluated as recorded decision processes, not merely as systems that produce final answers. In long tasks involving search, tool use, evidence inspection, and synthesis, an agent may introduce an unsupported claim early and then reuse it later as if it were established fact. Outcome-level evaluation can reveal whether the answer is right or wrong, but it cannot identify which span first made the trajectory unreliable. The authors frame this as span-level error localization: finding the consequential mistake inside ordered trajectory evidence. This focus is important because the visibly wrong part of a trajectory may be the final answer, while the actual cause may be an earlier commitment about an entity, constraint, source, candidate, or conclusion.
What the paper studies
To make this problem concrete, the paper converts raw agent logs into ordered semantic spans that capture coherent units of activity such as planning, retrieval, verification, comparison, computation, decision-making, recovery, and finalization. A span is labeled as an error only when it introduces, relies on, amplifies, or finalizes a mistaken, unsupported, contradicted, or prematurely committed judgment that affects the answer path. The annotation scheme explicitly separates harmful error spans from normal exploration, failed searches, tentative hypotheses, recovered mistakes, and tool noise. This distinction is central to the benchmark because deep-research logs are noisy by nature, and not every failed query or uncertain intermediate thought should count as a reliability failure. By using spans rather than raw events or whole trajectories, the paper creates an evaluation unit that is detailed enough to locate the first harmful commitment while remaining abstract enough to compare heterogeneous agent frameworks.

How they built the dataset
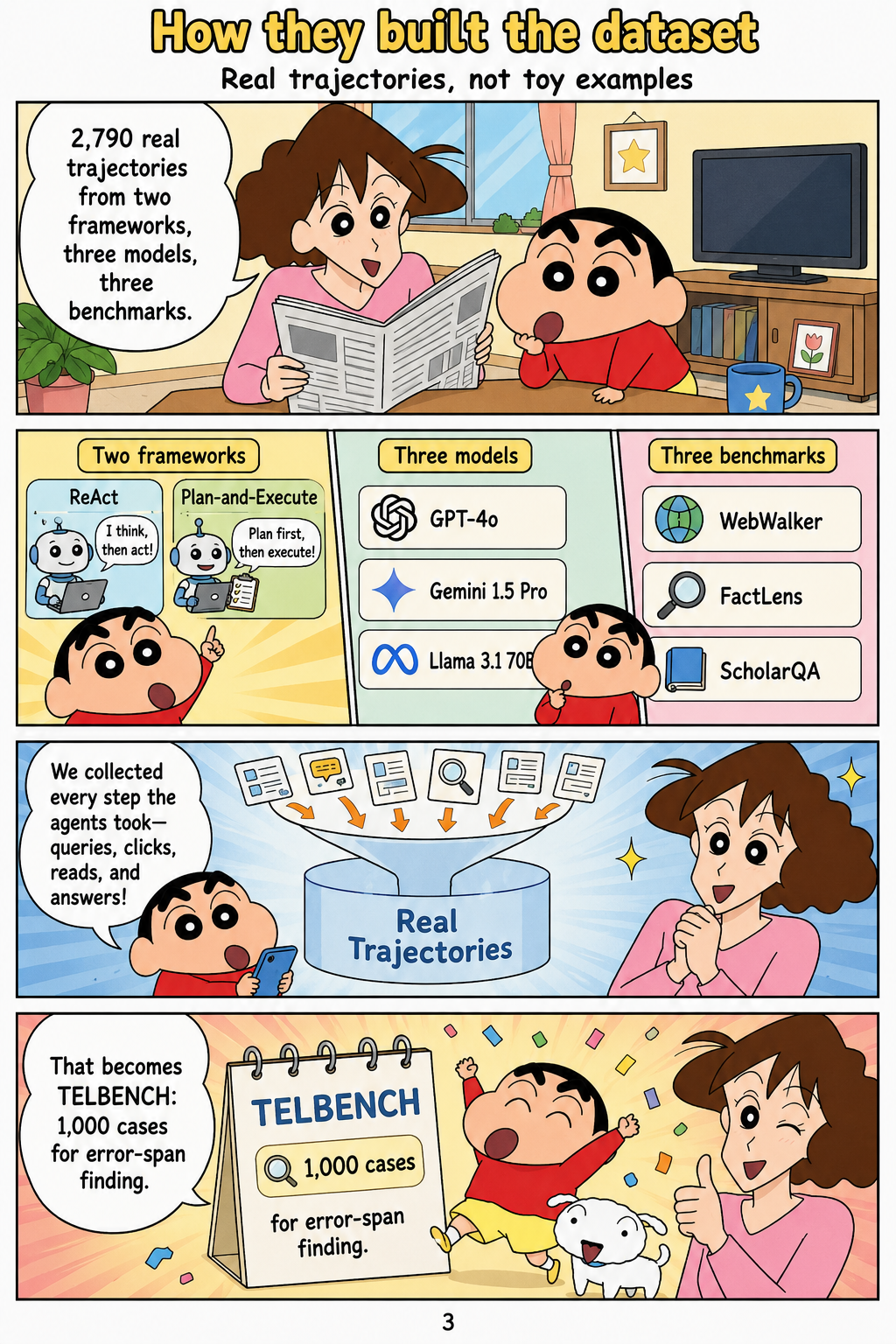
The dataset construction starts from 2,790 real deep-research trajectories generated across two agent frameworks, MiroFlow and OAgent, using three backbone models: GPT-5, Gemini-2.5-Pro, and Claude-Sonnet-4.5. The tasks come from GAIA-val, XBench, and BrowseComp-test, with BrowseComp downsampled so that it does not dominate the corpus, yielding 465 tasks before model-and-framework expansion. The authors normalize framework-specific logs, fold tool calls with results, reconstruct semantic execution order for nested multi-agent traces, and segment trajectories using changes in search target, candidate set, time scope, verification criterion, or reasoning objective. Error labels are produced through an LLM-assisted expert review pipeline in which two independent frontier-model annotators propose high-recall candidate error spans, and expert annotators verify, revise, add, and adjudicate labels against the full trajectory evidence. From these annotations, the paper builds TELBENCH, a 1,000-instance benchmark for identifying error and non-error spans and evaluating earliest harmful-span localization.
The key method: DRIFT
The paper’s main method, DRIFT, is a claim-centric auditing framework designed to overcome the instability of directly asking an LLM to inspect an entire long trajectory. DRIFT tracks the claims that an agent forms and uses, rather than scoring each span in isolation. A Claim Keeper maintains a claim ledger that records when claims are introduced, when they become consequential, and which later spans depend on them. A Support Seeker checks whether important claims are directly supported, weakly supported, missing support, or contradicted by trajectory evidence. Specialist Auditors then route checks over entity, constraint, evidence, retrieval, compute, and process claims, while a Dependency Tracer backtraces unsupported or conflicting claims to distinguish harmful errors from harmless noise.

Why it matters
The experiments reported in the paper show that DRIFT improves span-level error localization and first-error accuracy by up to 30 percentage points across model families and auditing frameworks. This result supports the paper’s central claim that reliability diagnosis for deep-research agents requires process-level evidence, not just final-answer scoring or full-context prompting. TELBENCH also positions deep-research trajectory diagnosis as distinct from earlier process-evaluation benchmarks such as ProcessBench, PRMBench, DeltaBench, VisualProcessBench, AgentProcessBench, and TRAIL, because deep-research traces are longer, noisier, and more dependent on evolving evidence commitments. The paper’s mechanism analysis further annotates spans by workflow stage and error fault family, enabling analysis of where failures arise in planning, retrieval, verification, extraction, computation, decision-making, recovery, or finalization. The broader implication is that future deep-research systems need auditing tools that can identify the first consequential unsupported claim before it propagates into a plausible but unreliable answer.
