ReadPaper Blog
VIDEO2LORA: Parametric Video Internalization for Vision-Language Models
VIDEO2LORA addresses the high token cost of video understanding in vision-language models, where each frame consumes many visual tokens and repeated queries re-pay the same encoding cost. The paper proposes a Perceiver hypernetwork that converts a video into a LoRA adapter in one forward pass, allowing a frozen VLM to answer later text queries with zero visual tokens in context. Experiments with SmolVLM2 500M and 2.2B show comparable performance to direct video-in-context inference on captioning and most question-answering benchmarks while greatly reducing answer-time visual-token load and time to first token.
Source: VIDEO2LORA: Parametric Video Internalization for Vision-Language Models

The Video Token Traffic Jam
The paper begins from a concrete scalability problem in video-capable vision-language models: video is represented as long sequences of visual tokens, and every sampled frame can add hundreds of tokens to the context. This makes even short clips expensive, because memory and latency grow with both frame count and the number of repeated queries over the same video. The authors argue that the context window is not merely an engineering inconvenience but the fundamental bottleneck for video understanding, since overloaded VLMs can produce incoherent or repetitive outputs unrelated to the input video. Existing strategies such as frame subsampling, visual-token compression, long-context architectures, and streaming memories reduce pressure on the context but still leave visual information in the query-time context. VIDEO2LORA is motivated by eliminating this recurring token burden rather than managing it through more aggressive compression.
Not Compression, Internalization
The central shift in VIDEO2LORA is parametric video internalization: the video is converted into model parameters before downstream questions are asked. Instead of placing visual tokens beside every prompt, the method stores video-specific information in a generated Low-Rank Adaptation adapter attached to the frozen VLM. This differs from ordinary LoRA fine-tuning because the adapter is not learned through iterative gradient updates for each video; it is predicted directly from the video by a feedforward hypernetwork. The paper positions this as an extension of document-to-parameter ideas into a harder cross-modal setting, where high-volume visual evidence must be expressed as low-rank perturbations to a language model’s parameter space. The implication is that a single internalization step can amortize the cost of video processing across many later queries.

How VIDEO2LORA Works
VIDEO2LORA implements this idea with a frozen SmolVLM2 encoder, a frozen SmolVLM2 answer model, and a trainable Perceiver hypernetwork. Given a video and an internalization instruction, the frozen encoder produces layer-wise hidden states, denoted in the paper as a stacked representation across transformer layers, sequence positions, and hidden dimensions. The Perceiver-style resampler attends from learned latent queries to these video-conditioned hidden states, preserving layer information so that the generated adapter can be indexed by transformer layer rather than derived from a single pooled video vector. The hypernetwork outputs LoRA factors for selected linear modules, with the experiments applying generated adapters to the MLP down_proj modules of the text decoder at rank 16. During training, only the hypernetwork parameters are optimized with teacher-forced cross-entropy over response tokens, while both the encoder and answer model remain frozen.
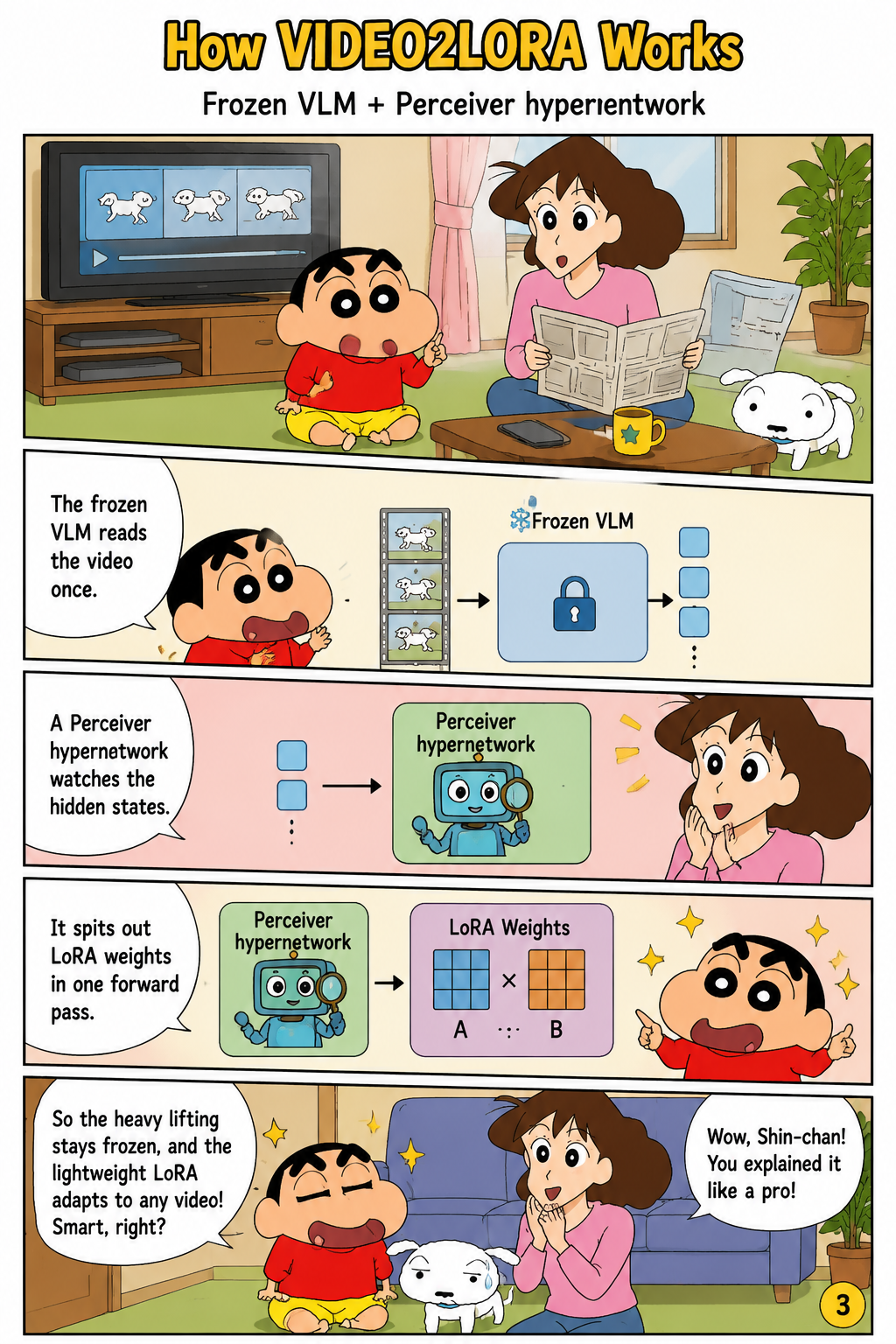
Ask Anything Later
At inference time, the generated LoRA adapter is attached to the frozen answer model, and downstream prompts are answered without supplying the original video frames or visual tokens. In the paper’s formulation, the answer distribution is conditioned on the text prompt and the video-specific adapter θ(v), while the video tokens themselves are absent from the context window. This makes per-query cost independent of video length after the one-time adapter generation step, which is especially important when many questions are asked about the same video. The method also separates video internalization from question answering: the video is read once to produce adapter weights, and later prompts can probe the internalized content through the adapted model. This design makes VIDEO2LORA orthogonal to token-pruning or long-context methods because it removes visual tokens from the answer-time context rather than merely reducing their number.

What the Experiments Say
The experiments evaluate VIDEO2LORA on SmolVLM2 500M and 2.2B using video summarization, captioning, and video question answering tasks, with training based on 12 uniformly sampled frames at 384px and teacher-generated targets from a frozen SmolVLM2 teacher. The paper reports statistical non-inferiority and equivalence to direct video-in-context inference across five captioning benchmarks: ActivityNet Captions, PLM-RDCap, PLM-RCap, VDC, and CaReBench. For video question answering, it reports equivalence across seven of eight benchmark-scale pairings involving NExT-QA, ActivityNet-QA, PLM-SGQA, and VidCapBench. A notable generalization result is that VIDEO2LORA remains stable up to 1,024 frames and 1024px despite being trained only at much smaller frame counts and resolution, whereas direct video-in-context inference often degenerates under such loads. Across this sweep, the method reduces answer-time visual-token load by up to 1,500× and query time to first token by 6–80×, and the authors also observe that independently generated adapters for non-overlapping video segments can compose in rank space, suggesting a path toward chunked long-video internalization.
