ReadPaper Blog
SWE-Explore: Benchmarking How Coding Agents Explore Repositories
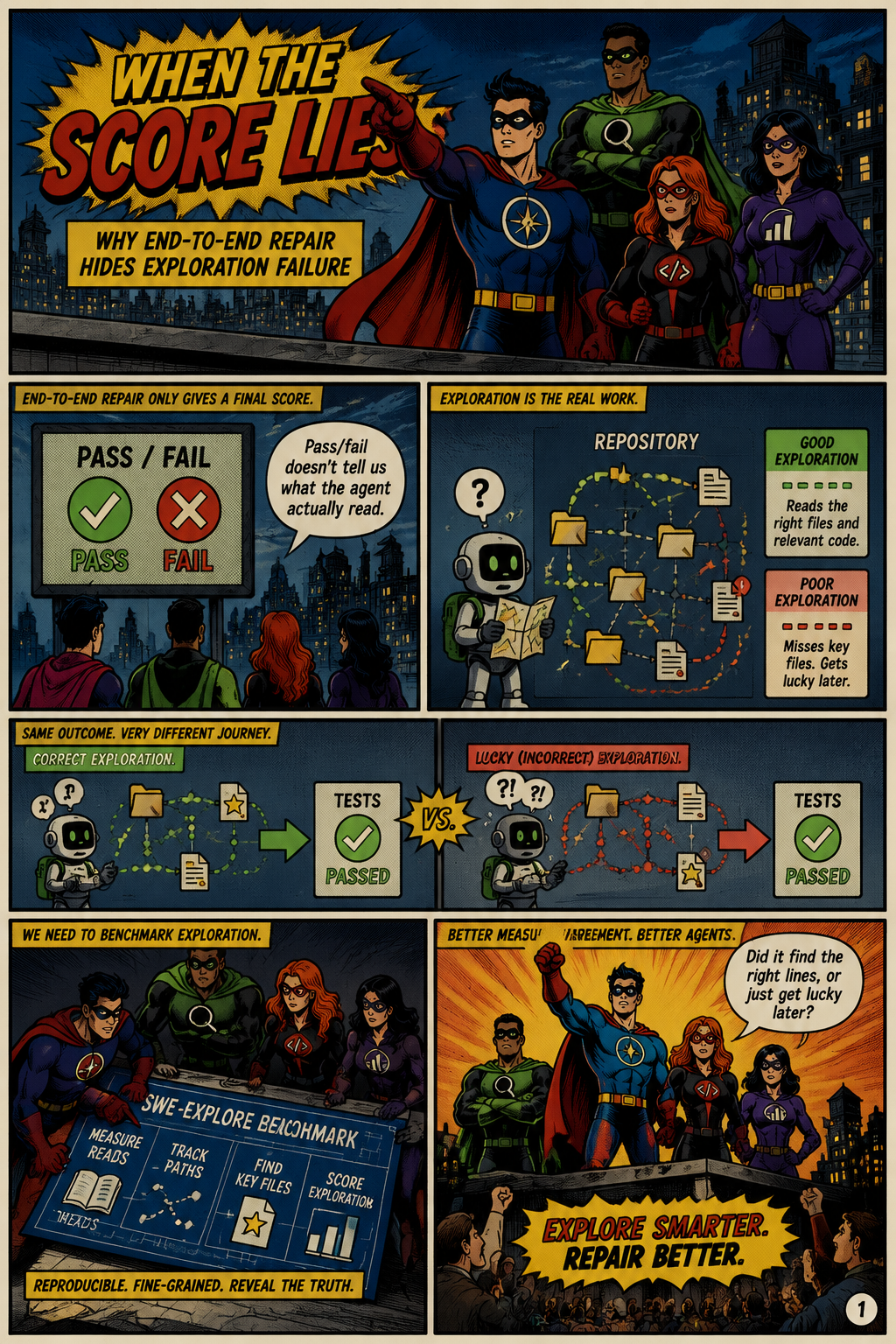
SWE-Explore is a benchmark for measuring how well coding agents find the relevant parts of a software repository before attempting a repair. The paper addresses a limitation of end-to-end benchmarks such as SWE-bench: a pass/fail repair score cannot distinguish failure to read the right code from failure to synthesize a correct patch. Its approach asks explorers to return ranked line-level code regions under a fixed budget, then evaluates those regions against trajectory-grounded supervision and validates that the metrics track downstream repair behavior.
Source: SWE-Explore: Benchmarking How Coding Agents Explore Repositories
When the Score Lies
The paper argues that repository-level coding benchmarks have made automated repair measurable, but their holistic resolve-rate metrics hide the mechanisms behind success and failure. In benchmarks such as SWE-bench, SWE-bench Verified, SWE-bench Multilingual, and SWE-bench-Pro, a coding agent ultimately receives a binary outcome: the patch either passes the test harness or it does not. SWE-Explore identifies a crucial blind spot in that protocol, because an agent may fail because it never explored the relevant code, or because it found enough evidence but still generated an incorrect fix. The authors motivate repository exploration as a distinct capability involving repository understanding, context retrieval, code localization, and bug diagnosis. This distinction matters because real repositories contain many files and thousands of lines, so finding the decisive evidence is itself a difficult software-engineering task. By separating exploration from patch generation, the paper creates a way to diagnose whether coding agents are reading the right code before they try to write new code.
A New Target
SWE-Explore formalizes repository exploration as a ranked, line-level context selection task rather than an issue-to-patch task. Given an issue description and a repository snapshot, an explorer returns a ranked list of code regions, where each region is represented by a file path and a line range. The benchmark deliberately uses this simple output format so that sparse retrievers, dense retrievers, rerankers, long-context selectors, specialized localizers, and interactive coding agents can all be compared as producers of ranked regions. The fixed line budget makes the task about prioritizing useful evidence, not merely dumping large parts of the repository into context. The paper frames this design as complementary to executable repair benchmarks, because SWE-Explore does not require the explorer to write a patch or validate a fix. Its central measurement question is whether the explorer surfaces the relevant lines, and whether it surfaces them early enough to be useful.

Ground Truth from Real Solvers
A key methodological contribution of the paper is its trajectory-grounded supervision for line-level ground truth. Instead of relying only on manually written labels or coarse file-level targets, SWE-Explore derives relevant line regions from independent coding-agent trajectories that successfully solved the same issue. The construction process extracts read actions from solution-verified runs, including repository interactions such as tool views, shell reads, and grep hits, and distills the specific code regions consulted during successful solution paths. The paper describes aggregating these regions into higher-confidence core context and lower-confidence optional context, with human quality assurance used for correctness, deduplication, and finalization. This design attempts to capture not just where the final patch was applied, but what evidence successful agents actually used while navigating the repository. The resulting benchmark covers 848 issues across 10 programming languages and 203 open-source repositories, giving the evaluation multilingual and multi-repository scope.

How It Is Measured
The paper evaluates exploration quality through coverage, ranking, and context-efficiency metrics. Coverage asks whether the returned regions include the trajectory-grounded relevant lines, while ranking measures whether those lines appear early in the ordered output, using the same intuition behind ranked retrieval measures such as nDCG and Rank@k. Context efficiency captures how effectively an explorer uses a limited line budget, which is important because large but poorly prioritized context can still leave a patching agent without the decisive evidence. The authors emphasize line-level scoring because file-level or function-level localization can overstate success when a method reaches the right neighborhood but misses the crucial span. SWE-Explore’s comparison table positions the benchmark as distinct from Loc-Bench, ContextBench, SWE-ContextBench, and SWE-bench variants because it combines multilingual coverage, line-level ground truth, trajectory-grounded labels, ranked-region evaluation, and a downstream repair check. The metrics are therefore designed to evaluate the exploration step directly while remaining comparable across very different retrieval and agentic methods.

Why It Matters
The paper validates the practical meaning of its exploration metrics through a restricted-context repair protocol. In this protocol, each explorer’s ranked output is used as the only repository context available to a fixed coding agent, and the resulting patch is evaluated with the original test harness. This setup checks whether higher exploration scores correspond to better downstream repair behavior while keeping patch generation constant across explorers. The reported finding is that coverage, ranking, and context-efficiency metrics strongly track downstream repair behavior, supporting the claim that line-level exploration quality is not merely an abstract retrieval score. Across classical retrieval methods, general coding agents, and specialized localizers, the paper finds that agentic explorers form a clear tier above classical retrieval, while modern methods are already relatively strong at file-level localization. The authors conclude that line-level coverage and efficient ranking are the key axes that differentiate state-of-the-art repository explorers, making SWE-Explore a diagnostic complement to end-to-end coding-agent benchmarks.
