ReadPaper Blog
Role-Agent: Bootstrapping LLM Agents via Dual-Role Evolution
Role-Agent addresses a central limitation in training LLM agents: sparse feedback and static environments often fail to reveal why an agent made poor long-horizon decisions. The paper proposes using a single LLM in two roles, as both the acting agent and an adaptive environment-like critic, through World-In-Agent state prediction and Agent-In-World failure-driven task redistribution. Experiments on multiple benchmarks report consistent gains, including an average improvement of over 4% against strong baselines, suggesting that dual-role co-evolution can improve agent learning without requiring separate environment models.
Source: Role-Agent: Bootstrapping LLM Agents via Dual-Role Evolution

When agents get stuck
The paper starts from the observation that LLM agents increasingly operate in multi-turn settings such as coding, navigation, deep research, and embodied tasks, where final success depends on long-horizon interaction rather than one-shot answering. Existing Agentic Reinforcement Learning methods can optimize full rollout trajectories, but many environments provide sparse trajectory-level rewards that say little about which action caused failure. The authors argue that static training environments also fail to expose hidden weaknesses because they present tasks, observations, and rewards without adapting to the agent’s current deficiencies. This creates inefficient exploration: the agent may repeat familiar behaviors while receiving feedback too coarse to support fine-grained credit assignment. Role-Agent is motivated as a way to make the learning environment more informative and adaptive while avoiding the extra complexity of building separate synthetic environment models or task generators.
One model, two roles
Role-Agent proposes bootstrapped agent-environment co-evolution by assigning a single LLM two complementary functions during training. In one role, the model acts as the agent, choosing actions under a policy and interacting with task states across a trajectory. In the other role, the same model contributes environment-like feedback by analyzing failures and reshaping which tasks should be emphasized in later training. This design differs from agent-only self-improvement methods because the paper treats the training distribution itself as something that can adapt to the agent’s weaknesses. The framework is organized around two modules, World-In-Agent and Agent-In-World, which together aim to improve both environment-aware reasoning and targeted practice. The implication is that an LLM agent can use its own generative and analytic capacity to create richer learning signals without relying on additional human supervision.

World-In-Agent
World-In-Agent internalizes environment dynamics by asking the LLM agent to predict future states after each action during a rollout. Formally, after action at step t, the agent predicts states over a horizon H, producing future-state estimates that are later compared with the actual observed states. The paper measures this prediction quality using a Longest Matching Subsequence score over textual state contexts, yielding predictive rewards that quantify how well the agent anticipated action consequences. These predictive rewards are not added as independent success signals; instead, they modulate the task reward through a multiplicative form, so accurate prediction amplifies credit for successful actions while poor prediction weakens credit for actions whose success may be accidental. This mechanism turns state prediction into a reliability-aware process reward, encouraging the agent to reason about how actions change the environment rather than merely optimizing final outcomes.

Agent-In-World
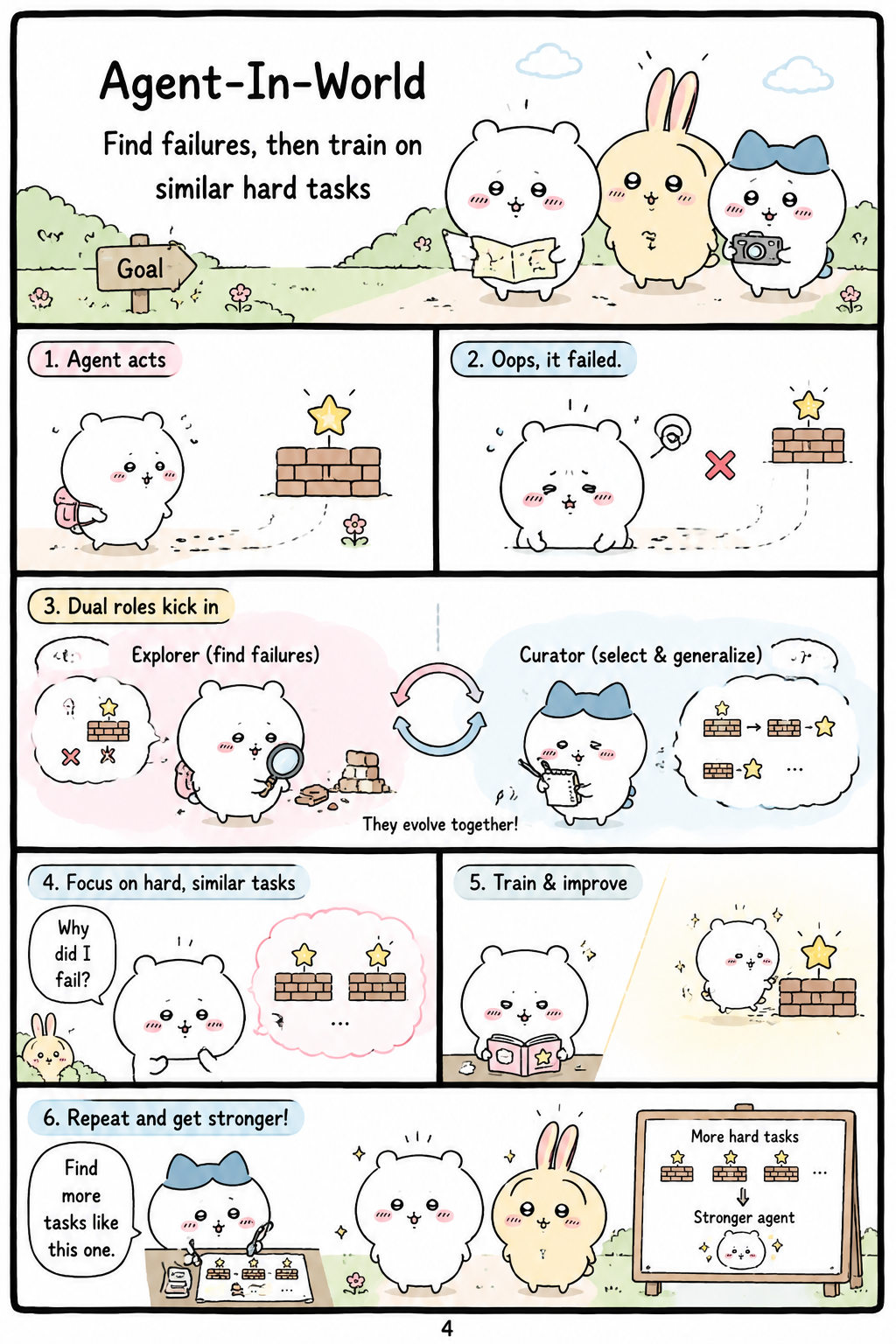
Agent-In-World addresses the complementary problem of deciding what the agent should practice after it fails. The module uses the same LLM to examine failed trajectories step by step and produce reflections or failure modes that identify root causes of unsuccessful behavior. Role-Agent then retrieves tasks with similar failure patterns and adjusts the training data distribution toward those cases, making the environment more diagnostic of the agent’s current weaknesses. This approach is positioned against fixed-distribution RL and self-evolving agent methods that mainly update policies or agent scaffolds while leaving the task environment unchanged. By prioritizing tasks linked to historical deficiencies, Agent-In-World gives the training process a curriculum-like adaptation driven by observed failure rather than manually designed scheduling. The result is a feedback loop in which poor performance is converted into information about where future rollouts should concentrate.
What changed?
The paper reports that Role-Agent consistently outperforms existing approaches across multiple benchmarks, with an average gain of over 4% over strong baselines. The authors interpret these results as evidence that a single LLM can use dual-role evolution to improve practical performance in text-based interactive environments. The reported gains support the value of combining fine-grained predictive credit assignment from World-In-Agent with failure-aware task redistribution from Agent-In-World. The method also has a deployment advantage because it avoids the need for separate environment models, task generators, or manually engineered adaptive schedulers. More broadly, the paper suggests that future LLM agent training can move beyond static rewards and fixed task pools toward self-adaptive interaction loops in which the agent learns both from what happened and from why its own predictions and decisions failed.
