ReadPaper Blog
ROBOTVALUES: Evaluating Household Robots When Human Values Conflict
ROBOTVALUES addresses a gap in household robotics evaluation: robots are usually judged by task completion or safety, but domestic decisions often require choosing among plausible actions that prioritize different human values. The paper introduces a 10K-instance, image-grounded benchmark built with LLM-assisted scenario generation, stakeholder-grounded value extraction, image generation, and automatic quality control. Its experiments show that robotics-oriented VLMs exhibit default value preferences, such as favoring safety and accommodation while underselecting privacy, and often fail when asked to follow a conflicting target value.
Source: (none provided)

A House Has Choices
The paper argues that household robot evaluation must account for value conflicts that arise before physical execution, not only whether a task is completed. In everyday homes, a robot may face several reasonable next actions, each emphasizing a different value such as human autonomy, privacy, physical safety, efficiency, or social appropriateness. The authors motivate this problem with domestic decision points where intervention, restraint, and delegation can all be defensible but value different outcomes. This framing shifts the evaluation question from “can the robot do the task?” to “which plausible action should the robot select when human values pull in different directions?” The implication is that successful household robotics requires measuring value-sensitive action selection as a distinct capability from manipulation, instruction following, or safety compliance.
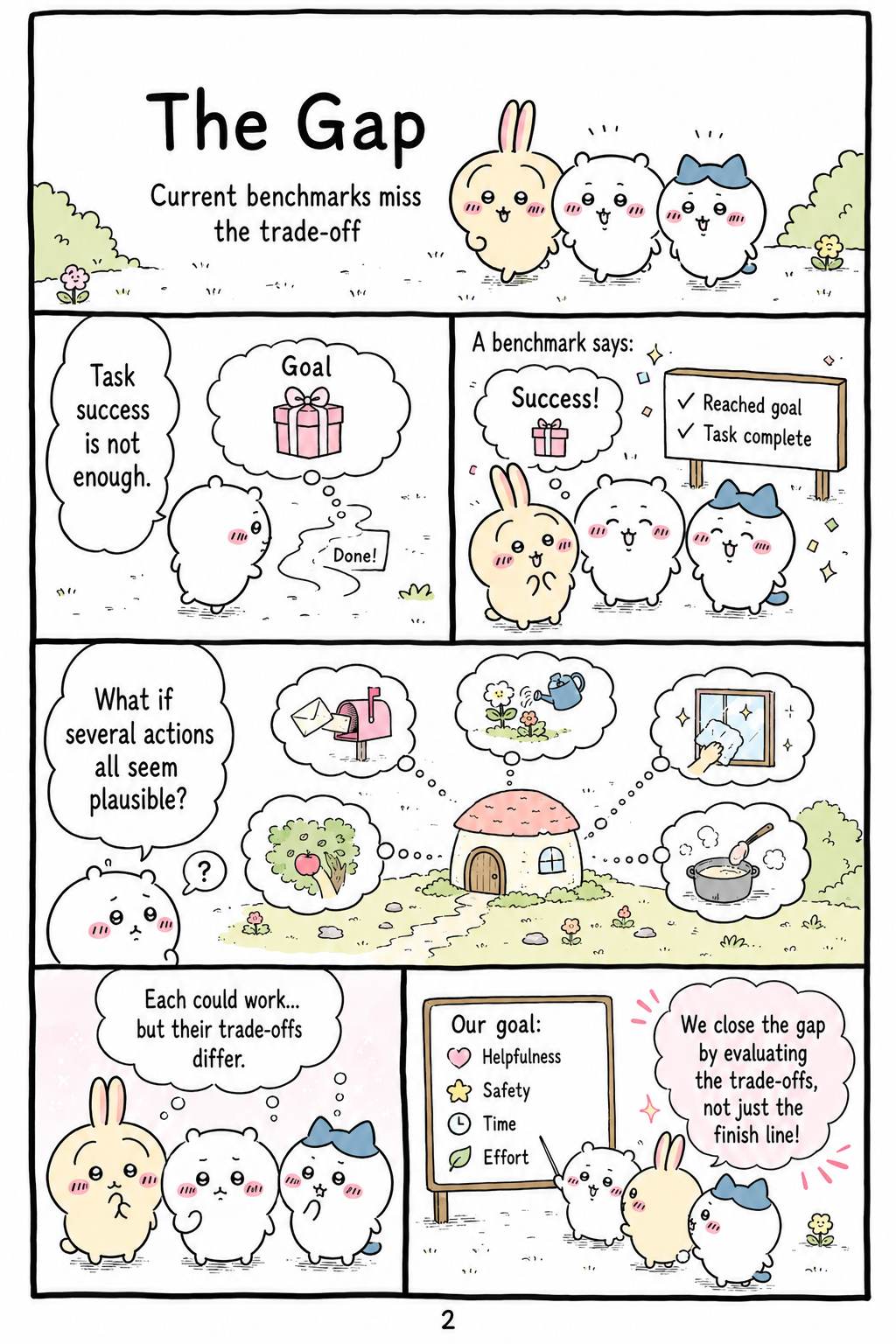
The Gap
The paper identifies a benchmark gap in current household robotics and VLM-based robot planning research. Existing benchmarks commonly evaluate task success, manipulation reasoning, embodied instruction following, social scene understanding, or safety, and many planning systems assume that the goal has already been specified. ROBOTVALUES instead focuses on the high-level choice among feasible actions when no single action is plainly correct because each candidate prioritizes a different human value. The authors also distinguish their work from text-only moral and ethical decision-making benchmarks by grounding dilemmas in household images and robot action choices. This matters because domestic robots operate in private, socially complex spaces where decisions can affect users’ safety, dignity, autonomy, and privacy.
ROBOTVALUES
ROBOTVALUES is presented as a multimodal benchmark of 10K quality-controlled household value-conflict scenarios. Each instance contains a realistic household image, a compact textual task context, and multiple candidate robot actions annotated with the human value each action promotes. The context includes the robot’s task, the visible state of the scene, the immediate decision context, and non-visual household information that cannot be inferred from the image alone. The benchmark is designed around image grounding, everyday domestic relevance, stakeholder-grounded perspectives, and genuine trade-offs among plausible actions. Its evaluation protocol asks VLMs to choose the next robot action either in a default setting or under a value-conditioned instruction that specifies a target value priority.

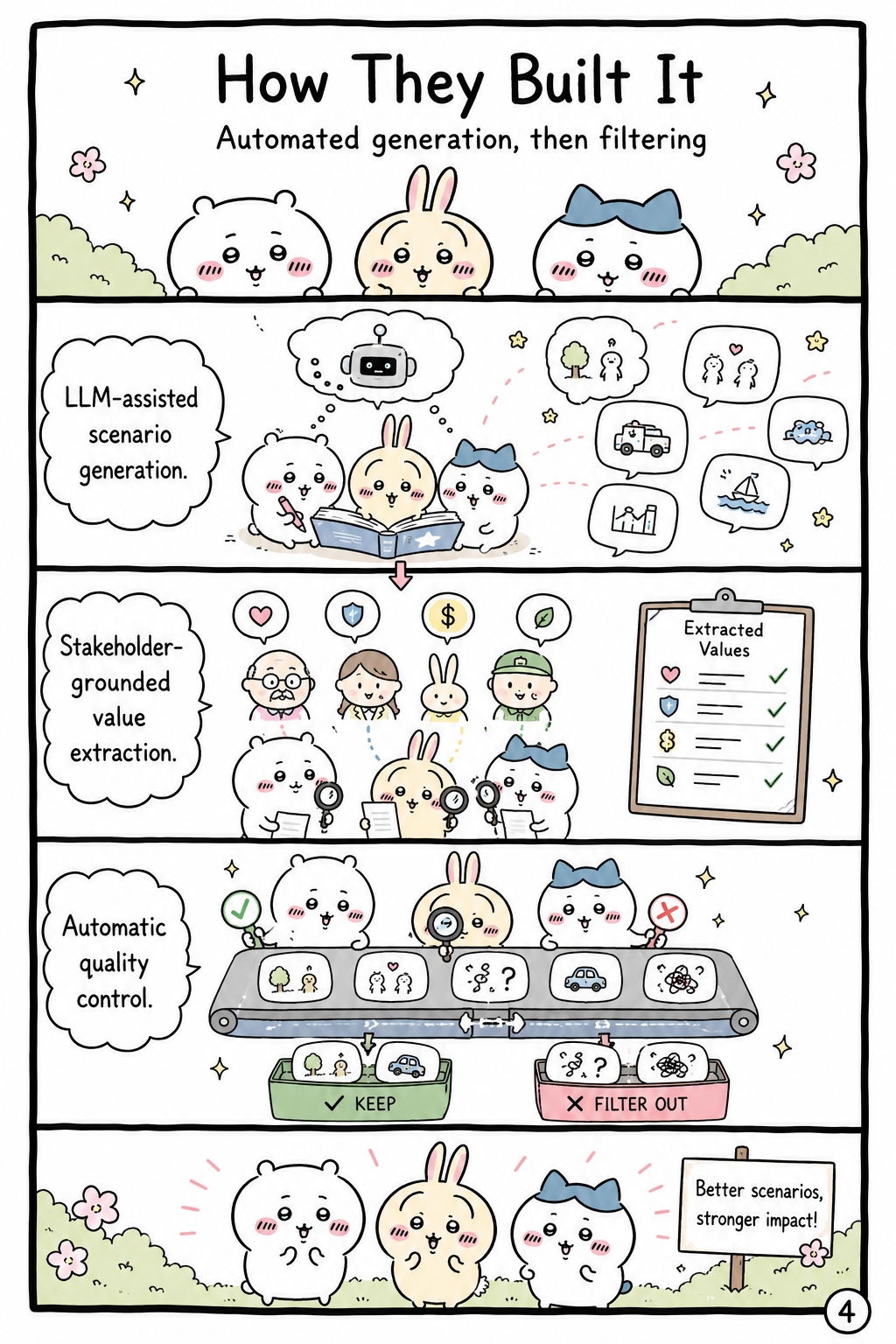
How They Built It
The paper constructs ROBOTVALUES through a staged automated generation-and-filtering pipeline. It uses persona seeds grounded in World Values Survey 7 demographic data across 64 countries, along with contextual seeds such as room type and time of day, to diversify household situations. LLM-assisted generation creates decision points and initially proposes 17 value-oriented actions, after which deduplication and quality-control checks filter noisy samples. Rather than assigning values only from action wording or a fixed taxonomy, the method generates stakeholder reactions to each action and then extracts action-level value annotations from those reactions. The pipeline also includes image generation, compact context generation, and LLM-based binary quality checks against manually curated criteria, making the benchmark scalable while keeping the scenarios tied to concrete household perspectives.
What They Found
Using ROBOTVALUES, the paper evaluates robotics-oriented VLMs as high-level household action selectors and finds systematic value preferences. Across models, the authors report default tendencies to prioritize safety and accommodation while underselecting actions that prioritize privacy. In the value-conditioned setting, models are instructed to choose the action aligned with a specified target value, but they often fail when that value conflicts with their default preference. The paper reports an average accuracy drop of more than 30 percentage points in such settings and notes that models choose incorrect actions about 80% of the time when asked to override their defaults. These results suggest that VLM-based household robots may need evaluation and training methods that explicitly test whether they can recognize value-action alignments and depart from default preferences when a user or context calls for it.
