ReadPaper Blog
Redesigning Mixture-of-Experts Routers with Manifold Power Iteration
This paper addresses a design gap in Mixture-of-Experts language models: standard routers choose experts with learned row vectors, but those vectors are not explicitly constrained to represent the experts they route to. It proposes Manifold Power Iteration (MPI), a “Power-then-Retract” router update that aligns each router row with the principal singular direction of its associated expert weight matrix, improving convergence, downstream performance, and load balancing in MoE pretraining from 1B to 11B parameters.
Source: Redesigning Mixture-of-Experts Routers with Manifold Power Iteration

Router, meet expert
The paper studies the router in Mixture-of-Experts models, where a sparse subset of expert feed-forward modules is activated for each input token. In the standard formulation, a router matrix maps a token representation into gating scores, applies TopK selection, and combines selected expert outputs through softmax weights. The authors emphasize that each row of the router matrix acts as a proxy for one expert, because token–router dot products determine token–expert affinity. This framing makes router design central to MoE efficiency: if the proxy vector poorly reflects the expert, sparse activation may select experts for the wrong reason. The paper’s motivation is therefore not to change the MoE interface, but to make the router’s learned geometry more faithful to the expert modules it controls.
The gap
The key gap identified by the paper is that conventional linear routers lack an explicit principle forcing router rows to encode the intrinsic features of their corresponding experts. A row vector in the router has limited expressivity, yet it is expected to summarize an expert whose parameters are matrices such as the Gated Linear Unit weights. The authors argue that this missing constraint can weaken both training convergence and final model competence, because token affinity is computed against a proxy that may not preserve the expert’s dominant structure. In the paper’s notation, the i-th router row R[i] should represent the associated expert weights W_i, but ordinary training does not guarantee such coupling. This diagnosis reframes routing as a compression problem: each expert matrix needs a mathematically meaningful vector representative.

Core idea
The paper’s central design principle is to align each router row with the principal singular direction of its associated expert weight matrix. This choice is justified through linear algebra: the top singular direction captures the most informative direction of a matrix, making it a natural compressed representation of an expert’s parameters. The authors express this objective through a Rayleigh-quotient-style projection, maximizing the squared norm of R[i]W_i relative to the router row norm. Exact singular value decomposition would be too expensive to perform for all experts during large-scale MoE training, so the paper uses power iteration as a lightweight online approximation. In this view, the router no longer learns as an unconstrained scoring table; it is continuously nudged toward the dominant geometry of the expert it is supposed to identify.
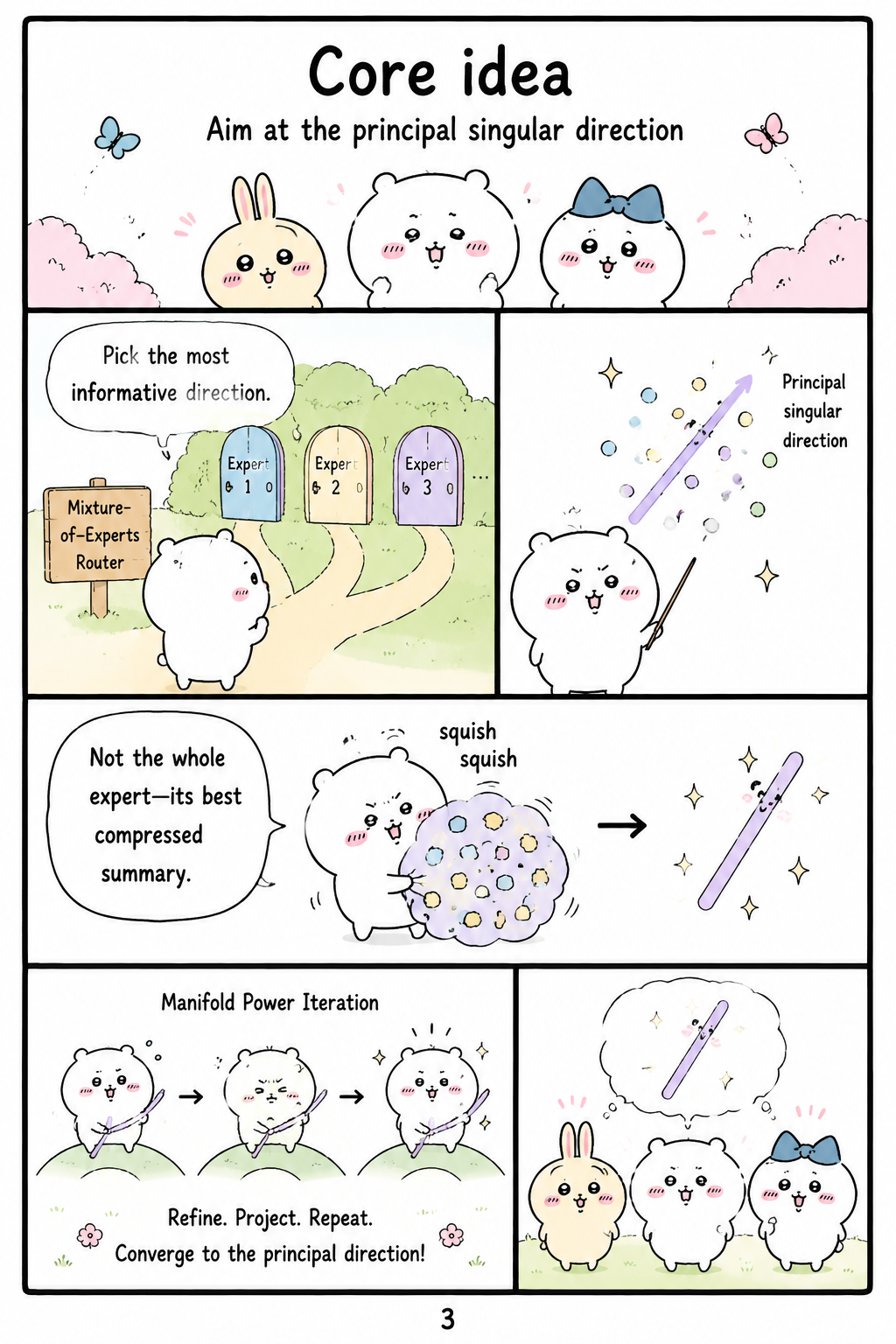
How MPI updates
Manifold Power Iteration implements this principle with a “Power-then-Retract” update. For each router row, the method performs one power-iteration step using the associated expert weights, written in the excerpt as R_hat[i] = R[i] W_g^i W_g^{iT}, which can be computed through standard matrix-vector products rather than full factorization. The update is followed by an L2 retraction that normalizes each router row to a controlled norm C, keeping the row on a spherical manifold and preventing numerical explosion or collapse. The paper further argues that the norm constraint mitigates expert bias caused by scale disparities, because an oversized router row can inflate gating logits and overload its expert. To keep routing logits at a constant scale as the number of experts N changes, the method sets C proportional to 1/sqrt(N) through a scale-invariant hyperparameter C′.

What it achieved
The paper supports MPI with both theoretical and empirical evidence. Theoretically, it shows that the online update behaves like steepest-ascent optimization of the maximum-projection objective under minimal-update and norm-preserving constraints, driving router rows toward the principal singular directions of their associated experts. Empirically, the authors report extensive MoE pretraining experiments across model scales from 1B to 11B parameters using billions of tokens. Across these settings, MPI is reported to produce faster convergence, stronger downstream performance, and improved load balancing compared with conventional router design. The implication is that router–expert alignment is not merely an implementation detail but a structural design principle for more effective sparse large language models.
