ReadPaper Blog
Qwen-Image-Flash: Beyond Objective Design
Qwen-Image-Flash studies how to distill a large visual generative model into a fast few-step student for both text-to-image generation and instruction-guided image editing. The paper argues that performance depends not only on the distillation objective, but also on the training recipe: data composition, teacher guidance, and task mixture. Using Qwen-Image-2.0 and DMD-based few-step distillation, the authors develop Qwen-Image-Flash, a unified model that operates with only 4 function evaluations.
Source: Qwen-Image-Flash: Beyond Objective Design

Beyond the Objective
The paper addresses a practical bottleneck in modern visual generative models: strong diffusion and flow-based systems can generate high-quality images, render structured visual text, and support editing, but they typically require many sampling steps. Few-step distillation offers a way to compress a multi-step teacher into a faster student, yet the authors argue that prior work has concentrated too narrowly on objective design. They use Qwen-Image-2.0 as the representative teacher and build on DMD, a distribution matching distillation objective, to study what else determines student quality. The central claim is that data composition, teacher guidance, and task mixture can substantially shape the outcome of distillation even when the objective is held fixed. This matters because a model intended for interactive editing, on-device generation, or large-scale visual content production must preserve visual capability while reducing latency and computation.
Question: What Actually Helps?
The paper frames few-step distillation as a training-pipeline problem rather than a loss-function-only problem. Its method begins from flow matching, where a model learns a velocity field along a path between data and noise, and then adopts DMD to align a conditional student generator with a pretrained multi-step teacher. In the DMD setup described by the authors, the student output is perturbed at intermediate noise levels, and the training signal depends on the difference between the score field of the student distribution and the score field supplied by the teacher. This framework lets the authors isolate training-time design choices while keeping the underlying distillation machinery consistent. The empirical study then examines text-to-image distillation, complementary teacher guidance, and joint generation-editing distillation as three places where seemingly ordinary recipe choices can produce unexpected behavior.

Data Diversity Can Surprise You
The paper’s analysis of text-to-image data composition shows that more diverse or more target-specific training data is not automatically better for few-step distillation. The authors construct prompt sets with Qwen3 across landscapes, portraits, and text-centric scenarios, with 20,000 prompts per category, and train 4-NFE students from Qwen-Image-2.0-Base under the same optimization protocol. They compare landscape-only, portrait-only, text-centric-only, landscape-portrait, and mixed-category training compositions on T2I-Bench, including landscape, portrait, and text-centric splits. The reported results show a counterintuitive pattern: text-centric-only and mixed-category data can underperform, while coherent single-category data such as portrait or landscape prompts can transfer well across evaluation categories. This finding implies that few-step distillation is sensitive not just to data volume or apparent coverage, but to the coherence and compatibility of the data distribution used to train the student.

Two Teachers, One Student
The paper also studies how to use teachers with complementary strengths without destabilizing few-step training. Its motivation is that advanced visual systems often have different downstream capabilities, and a single teacher may not be uniformly strongest across all aspects of generation and editing. The authors observe that directly combining knowledge from multiple teachers is challenging because their guidance can conflict or vary in usefulness across sampling steps. To address this, they propose step-wise multi-teacher guidance, a strategy intended to combine task-specific teacher expertise while preserving the stability of the distillation process. The broader implication is that teacher selection and scheduling are part of the distillation recipe, not a secondary implementation detail, especially when the target student must retain broad visual abilities under only a few function evaluations.

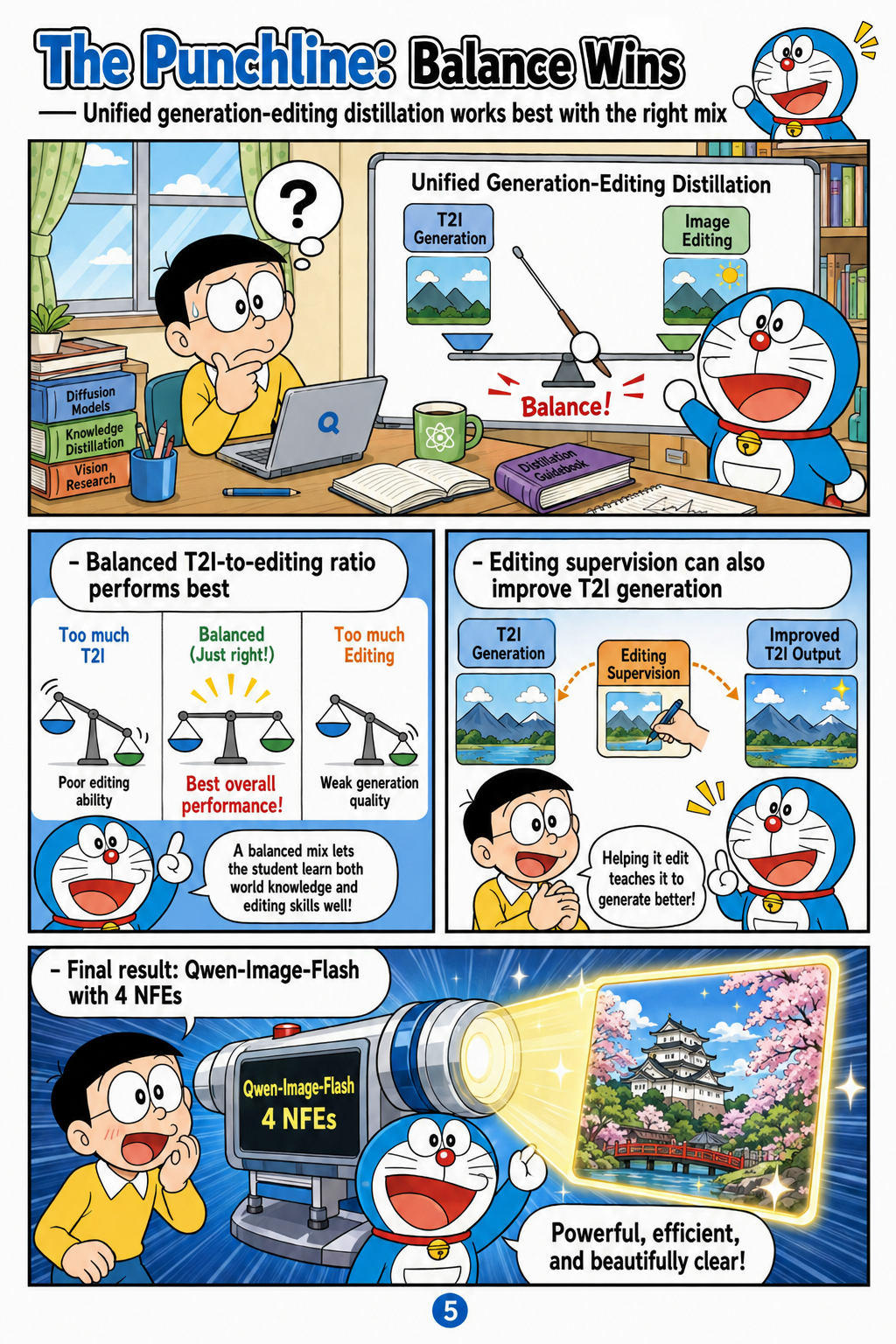
The Punchline: Balance Wins
For unified text-to-image generation and instruction-guided image editing, the paper finds that the task mixture is decisive. The authors introduce an Editing-Bench evaluation setting and study how different ratios of T2I and editing data affect joint distillation. Their main finding is that balanced T2I-to-editing data yields the strongest unified performance, while skewed mixtures can damage one side of the model’s capability. The paper further reports that editing supervision can benefit text-to-image generation, suggesting that instruction-guided edits provide useful visual and semantic constraints rather than merely competing for capacity. These results lead to Qwen-Image-Flash, a unified few-step generation-editing model designed to maintain strong synthesis and editing capability with only 4 NFEs.