ReadPaper Blog
Personal AI Agent for Camera Roll Visual Question Answering
The paper studies visual question answering over personal camera rolls, where an AI assistant must answer user-specific questions by searching and reasoning across hundreds or thousands of private photos accumulated over years. It introduces the camroll dataset, with 50 users, 31,476 images, and 2,500 manually annotated QA pairs, and proposes camroll-agent, a conversational agent with hierarchical memory and a compact tool set for navigating large-scale personal visual memory. The work matters because it shows that personalized visual memory is not solved by ordinary keyword search, generic image captions, or standard long-context methods.
Source: Personal AI Agent for Camera Roll Visual Question Answering

A tiny camera roll grows huge
The paper frames the personal camera roll as a dense autobiographical memory stream that is valuable but increasingly difficult to use. Smartphone users accumulate large collections of redundant, visually similar, and temporally scattered images, and the paper cites prior survey evidence that many people take photos to reflect later but feel overwhelmed when trying to retrieve specific moments. The central research problem is therefore not ordinary image recognition, but question answering over long-horizon personal visual history. The authors argue that camera rolls contain contextual records of daily life, events, meals, places, and relationships that conventional photo organization tools do not expose well. This motivation leads the paper to define personal camera roll VQA as a setting where an assistant must locate and interpret relevant images from a user’s own multi-year collection.
Why simple search is not enough
The paper explains that simple keyword search and generic similarity retrieval fail because many useful questions depend on event context, temporal order, and user-specific meaning rather than visible objects alone. A query such as what someone ate after watching the final Space Shuttle STS-135 launch requires connecting a NASA-related trip, the date of the launch, subsequent photos, and the meal appearing after that event. The authors contrast this with current photo search systems that can often retrieve images by places, faces, or objects but cannot reliably answer compositional questions grounded in personal chronology. They also note that retrieval-augmented generation methods designed for text can be misaligned with images when they treat each photo as an independent caption and discard raw visual details. The implication is that personal camera roll VQA requires reasoning over events, relationships, ownership, and recurrence, not merely matching query words to captions.

The paper’s answer: camroll
To make the problem measurable, the paper introduces camroll, a dataset built from real personal camera rolls and manually annotated questions that mimic realistic user interactions. The dataset contains 50 users, 31,476 images, and 2,500 question-answer pairs, giving researchers a benchmark for evaluating long-horizon personalized visual understanding. The paper positions camroll against prior resources that are either text-only personalization datasets, generic visual retrieval benchmarks, or photo-album retrieval datasets with simpler query structure. By using real user image streams, the dataset captures the messy properties of personal archives: repeated events, visual redundancy, incomplete textual descriptions, and questions that require personalized context. This contribution is important because the authors argue that the field lacks a standardized framework for evaluating AI assistants that reason over coherent personal visual histories.

camroll-agent looks through memory
The paper proposes camroll-agent as a conversational AI agent designed specifically for large personal photo collections. Its key design is hierarchical memory, which lets the system navigate visual information at different levels rather than attempting to place every high-resolution image into a multimodal model’s context window. The agent is also equipped with a minimal set of tools for searching and retrieving relevant information from the camera roll, reflecting the paper’s claim that different agent domains require different interaction patterns. This design directly addresses the impracticality of naively feeding thousands of images into an MLLM, since a single HD photo can cost thousands of tokens and a full camera roll can reach millions of tokens. By combining memory structure with targeted retrieval, camroll-agent aims to preserve visual and event-level context while keeping inference efficient.
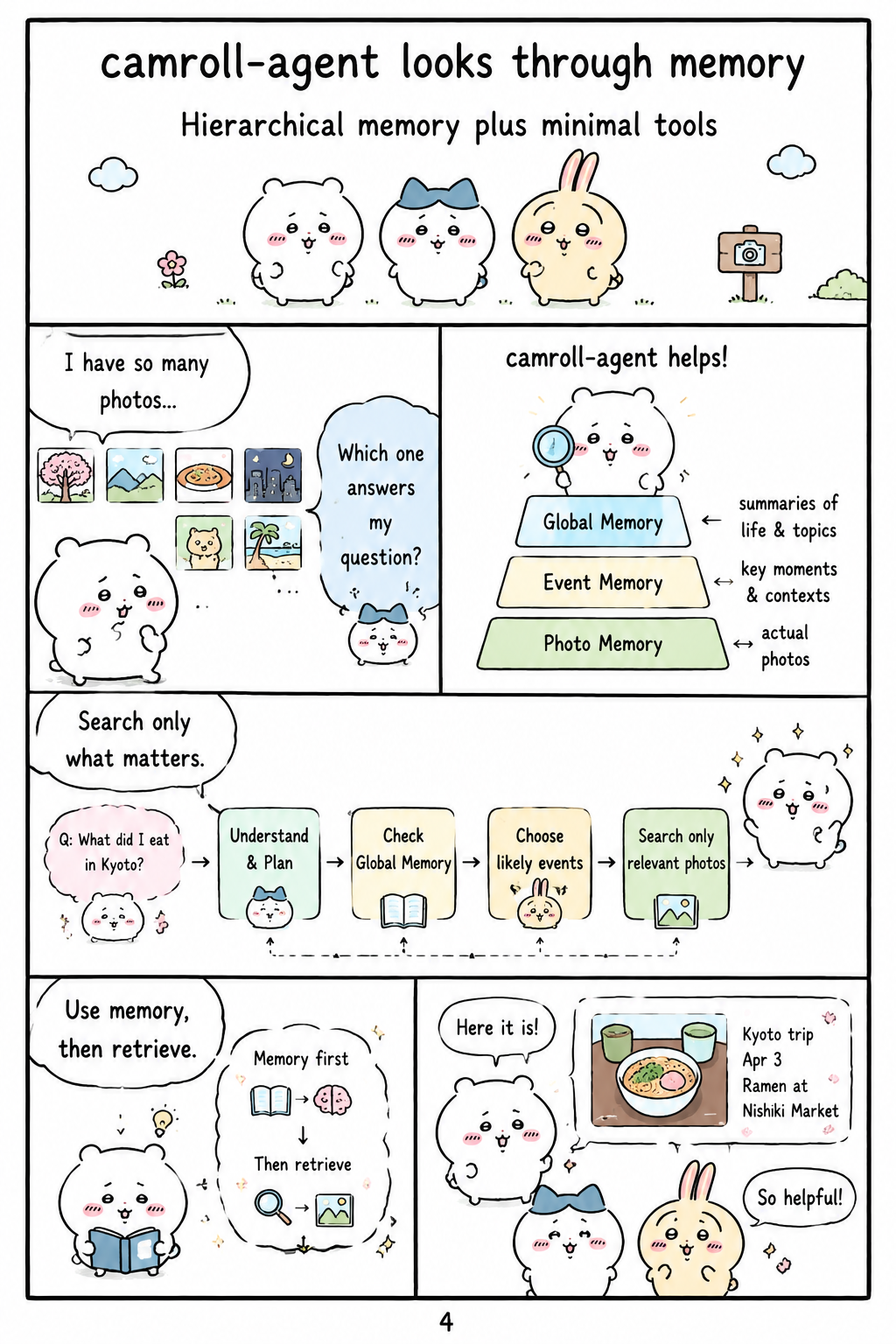
What the paper concludes
The paper’s experiments report that camroll-agent outperforms numerous baselines and long-context AI agent methods on the camroll benchmark. The authors interpret these results as evidence that personal visual memory poses a distinct challenge from standard long-context textual memory. In this setting, consistency, fine-grained visual details, user-specific concepts, event structure, and temporal relationships can all determine whether an answer is correct. The discussion argues that reducing images to generic captions loses information that is often essential for autobiographical reasoning, such as identities, relationships, and personally meaningful context. The broader implication is that future personalized AI assistants will need architectures and benchmarks tailored to long-horizon visual memory rather than relying only on larger context windows or conventional retrieval systems.
