ReadPaper Blog
OpenSkill: Open-World Self-Evolution for LLM Agents
OpenSkill studies how LLM agents can improve after deployment when they receive only a task prompt and environment, with no demonstrations, rewards, successful trajectories, curated skills, or verifier feedback. The paper proposes an open-world self-evolution framework that retrieves knowledge and verification anchors from documentation, repositories, papers, tutorials, and web resources, then uses them to build transferable skills and supervision-free virtual tests. Its significance is that it attempts to turn the open web into both a learning source and a practice environment while reserving hidden target-task supervision only for final evaluation.
Source: OpenSkill: Open-World Self-Evolution for LLM Agents

A Task Appears
The paper defines the central problem as open-world self-evolution for LLM agents: an agent must improve from only a natural-language task instruction and execution environment. Existing agent settings often assume that some useful learning signal is already available, but OpenSkill treats hidden target answers, ground-truth tests, rewards, verifier outputs, and solution traces as unavailable during skill construction. Formally, the paper represents each task as an instruction and environment pair, with a ground-truth test suite held back until final evaluation. The agent may not change its weights; instead, it augments behavior with an external skill set that conditions the base model at inference time. This framing matters because real deployments often expose the task input without exposing the feedback loop needed to know whether an attempted improvement worked.
Why Existing Loops Fail
The paper argues that prior self-evolving agent methods are limited because they usually rely on a learning loop that has already been supplied by humans, benchmarks, or successful prior executions. Human-written skills can be costly and incomplete, model-generated knowledge is bounded by the frozen model’s parametric memory, and skills distilled from successful trajectories require successes that may not exist at the start. Feedback-based approaches such as task-level critiques, verifier outputs, or reward signals can drive improvement in curated settings, but the paper emphasizes that such signals may be absent in open-world deployment. OpenSkill therefore separates two missing components: skill content, which specifies what the agent should learn, and a verification signal, which supplies a way to refine that content without target-task supervision. The key research question is whether an LLM agent can construct both components from independently accessible evidence rather than from hidden target answers.

OpenSkill’s Core Move
OpenSkill’s core contribution is to use open-world resources as the basis for both skill construction and verification construction. Given a task instruction and environment, the framework retrieves task-relevant knowledge from public documentation, code repositories, papers, tutorials, and web pages, producing knowledge documents that include concepts, APIs, best practices, source citations, and domain rules. It then synthesizes a structured skill plan that specifies the skill architecture and procedures the agent should follow. In parallel, it retrieves verification knowledge: independently checkable anchors such as reference values from official documentation, statistical invariants of known datasets, cross-validation procedures, domain standards, and expected output formats. The paper’s important distinction is that these anchors are not target answers; they are external facts used to build a practice signal without consulting the benchmark’s ground-truth verifier.

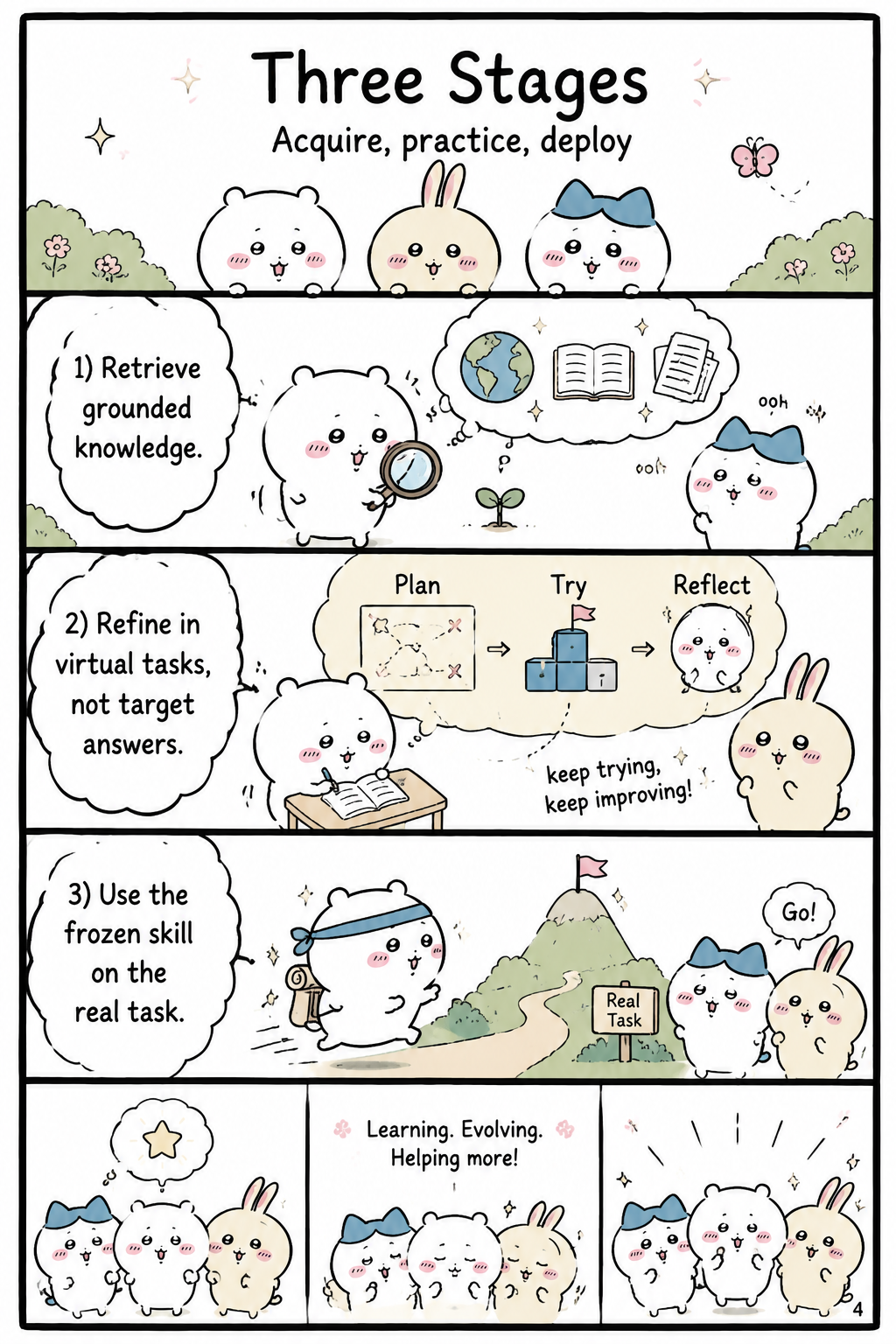
Three Stages
The OpenSkill pipeline has three stages: open-world knowledge acquisition, leakage-free skill evolution, and zero-shot target evaluation. In the first stage, retrieval functions collect task knowledge and verification knowledge from open-world sources, while filtering queries to avoid benchmark names or identifiers that could leak the hidden test. In the second stage, the base agent drafts an initial skill set from the retrieved knowledge and skill plan, then refines the skills jointly inside a sandbox using virtual tests built from the verification anchors. These virtual tests are deterministic assertions grounded in independently verifiable facts, such as known dataset properties, documented API behavior, or expected output structure, rather than guesses about the held-out target tests. In the final stage, the refined skill is frozen and deployed with the target agent, and only then is the hidden ground-truth test suite used to judge success.
Why It Matters
The paper reports that OpenSkill achieves the best automated pass rate across three benchmarks and two target agents while satisfying the no-target-supervision constraint during learning. In the excerpted results, the authors state that OpenSkill improves over the strongest closed-world baseline on SkillsBench by +8.9 and +8.8 in the two benchmark-agent settings, and that its verifier covers 88.9% of ground-truth test intents without accessing them. The analysis also claims that skills produced by OpenSkill transfer across models without model-specific adaptation, supporting the paper’s choice to evolve external skill artifacts rather than fine-tune model weights. These findings suggest that open-world evidence can provide not only factual knowledge but also a practical refinement environment for LLM agents. The broader implication is that deployable agent improvement may be possible under stricter and more realistic information constraints than prior self-evolution setups assume.
