ReadPaper Blog
MMAE: A Massive Multitask Audio Editing Benchmark
MMAE introduces a comprehensive benchmark for general-purpose, instruction-based audio editing, addressing the problem that prior evaluations are fragmented across narrow domains such as speech-only, sound-only, or basic edit operations. The paper builds a 2,000-sample testbed spanning multiple audio modalities, task complexities, granularities, and operation types, and evaluates outputs through 17,741 rubric-based criteria. Its results show that leading audio editing models still fail to execute reliable edits, with Exact Match Rate below 5% and reaching 0% in complex mixed-modality settings, making MMAE a diagnostic benchmark for future systems.
Source: MMAE: A Massive Multitask Audio Editing Benchmark

Why this benchmark?
The paper motivates MMAE by arguing that instruction-based audio editing has advanced faster than the infrastructure used to evaluate it. Existing benchmarks are described as fragmented, often limited to specific subdomains such as speech or sound effects, or to basic operations such as addition, removal, and replacement. The authors position audio editing as part of a broader shift toward interactive intelligent creation, where users express open-ended intentions in natural language and expect systems to modify speech, music, sound effects, or mixtures while preserving irrelevant context. MMAE is proposed to close this evaluation gap by serving as a comprehensive testbed for general-purpose audio editing rather than a collection of isolated task checks. The paper’s central claim is that robust evaluation must measure both data coverage and the quality of the evaluation paradigm, because open-ended editing requires nuanced perception, reasoning, generation fidelity, and preservation of acoustic structure.
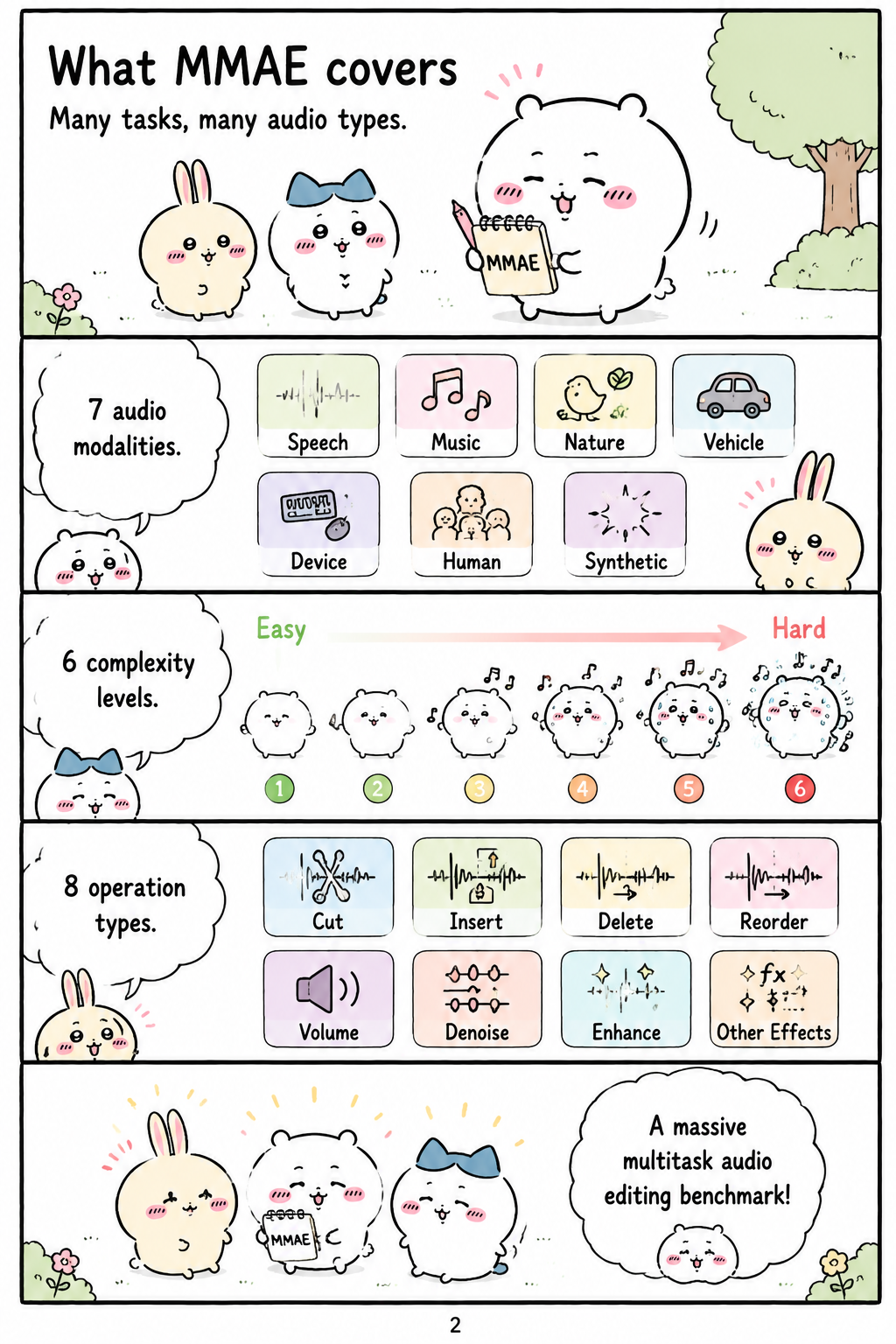
What MMAE covers
MMAE’s coverage is organized through a systematic taxonomy intended to stress-test real audio editing capabilities across domains and difficulty levels. The benchmark spans 7 audio modalities, including sound, speech, music, and mixtures such as music-speech and sound-speech settings. It also defines 6 levels of task complexity, ranging from simple edits to multi-hop reasoning, multi-audio editing, multi-instruction editing, and context-aware multi-round editing. The paper further distinguishes 2 granularity levels, local and global, so that models can be evaluated on edits confined to a time span or applied across an entire clip. Across these dimensions, MMAE includes 8 operation categories, allowing the benchmark to represent practical editing demands such as alteration, removal, replacement, foreground change, local addition, and global background change.
How the tasks are checked
The paper’s evaluation method replaces single-score judgments with a rubric-based framework designed for free-form audio editing instructions. Each audio-instruction instance is paired with tailored criteria that decompose the desired edit into verifiable questions about instruction following, content preservation, acoustic consistency, and output quality. Across the benchmark, the authors construct 17,741 such criteria for 2,000 high-fidelity samples, enabling multi-dimensional assessment rather than a coarse overall rating. The paper emphasizes that rubrics can check both the changed region and the unchanged context, such as whether speech content remains consistent, whether an edit affects the intended time segment, and whether the output introduces distortion, clipping, or noise. This design is presented as more interpretable and diagnostically useful than traditional metrics for open-ended editing, because it identifies which subrequirements of a complex instruction a model satisfies or fails.

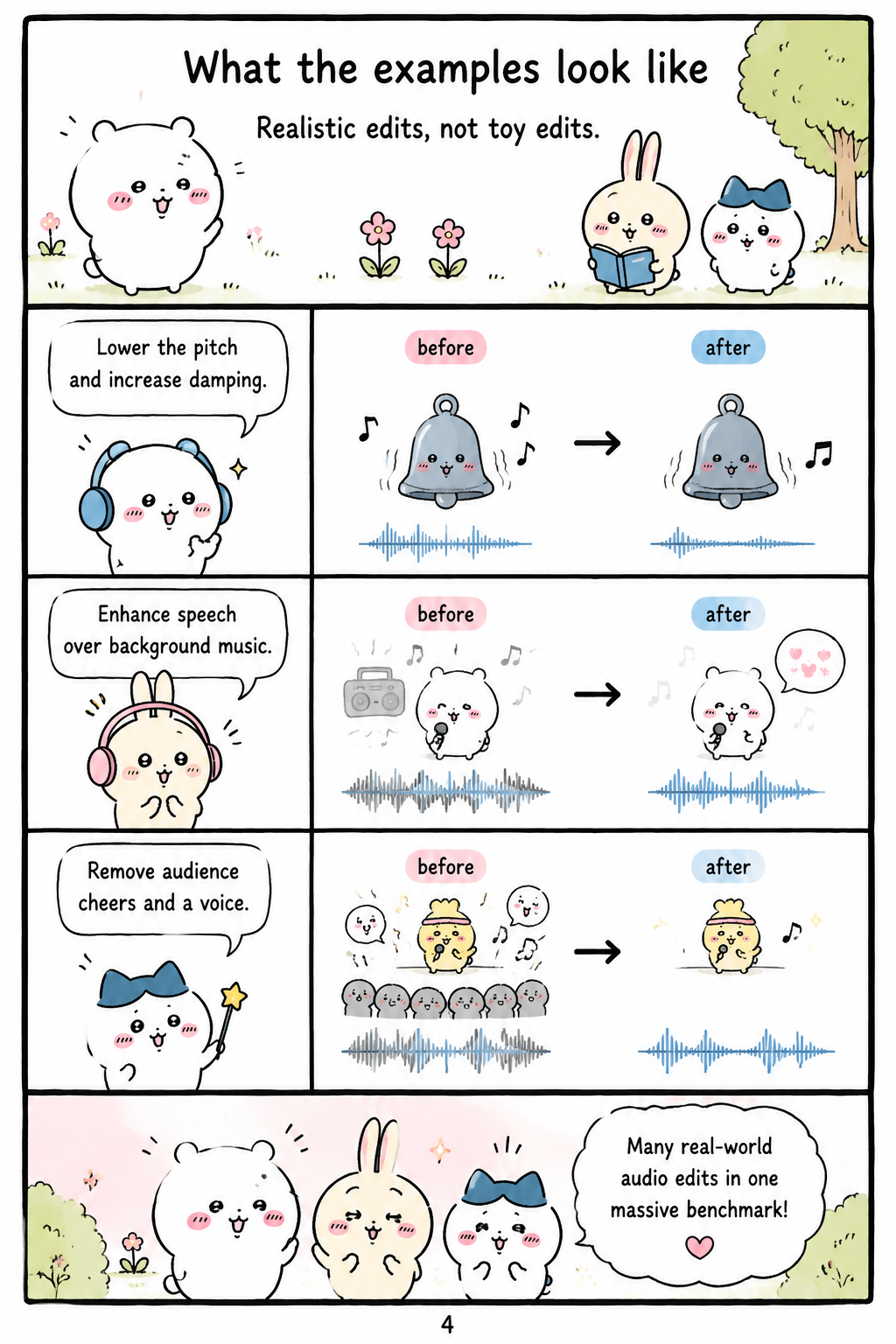
What the examples look like
The benchmark examples described in the paper illustrate why MMAE is framed as a realistic editing test rather than a narrow operation suite. One sound-editing task asks a model to alter the acoustic properties of a glass hit by lowering perceived pitch and increasing damping to simulate a higher water level, which requires physical and perceptual reasoning in addition to signal modification. A music-speech task asks the model to enhance speech over background music while preserving spoken content and avoiding global degradation, testing source balance rather than indiscriminate amplification. A sound-speech removal task requires eliminating audience cheers and a female speaker while preserving a male host’s content, probing selective separation and context preservation. Other examples include changing lyrics while transferring vocal timbre, reordering spoken author names across multiple editing rounds, and adding seagulls, soothing background music, and a specified spoken phrase, demonstrating the benchmark’s emphasis on compositional instruction following across modality mixtures.
Main takeaway
The paper’s empirical findings indicate that current audio editing systems remain far from reliable under the MMAE evaluation protocol. In evaluations of five recent audio editing models, the Exact Match Rate stays below 5% across systems and drops to 0% in complex mixed-modality scenarios. The authors interpret this gap as evidence that average metric competence can mask failures in flawless execution, especially when tasks require precise edits while preserving unrelated acoustic context. Their analysis identifies bottlenecks in instruction understanding, structural robustness, cross-domain synchronization, and generation quality, and reports that adding external agentic planners does not consistently improve outcomes. The paper concludes that MMAE can serve as a standardized, long-lasting evaluation paradigm and a diagnostic roadmap for building next-generation instruction-based audio editing models.
