ReadPaper Blog
LoomVideo: Unified Multimodal Video Generation and Editing
LoomVideo proposes a unified video generation and editing architecture that can interpret interleaved text, image, and video inputs while avoiding the high cost of prior large unified models. The paper addresses the inefficiency of source-token concatenation in video editing by introducing a compact 5B-parameter Diffusion Transformer system with Multimodal Large Language Model conditioning, Deepstack injection, Scale-and-Add editing, and Negative Temporal RoPE for multiple references. Its reported results show state-of-the-art or highly competitive performance, especially in e-commerce and fashion scenarios, with at least 5.41× faster inference than comparable concatenation-based unified models.
Source: LoomVideo: Unified Multimodal Video Generation and Editing

The Video Realm Needs One Hero
The paper frames unified multimodal video generation and editing as a practical need for applications such as digital entertainment, e-commerce, and controllable content production. Existing unified video frameworks can condition on text, images, and source videos, but the paper argues that many rely on very large models, typically 13B parameters or more, which makes training and inference costly. A central bottleneck identified by the authors is the common editing strategy of concatenating source-video tokens with target-video tokens. Because self-attention scales quadratically with sequence length, doubling the sequence length can quadruple the attention computation. LoomVideo is motivated by the question of whether a smaller unified model can preserve strong multimodal control while removing this editing overhead. The paper’s contribution is therefore not only a new generation model, but a redesign of how multimodal conditions enter video diffusion.
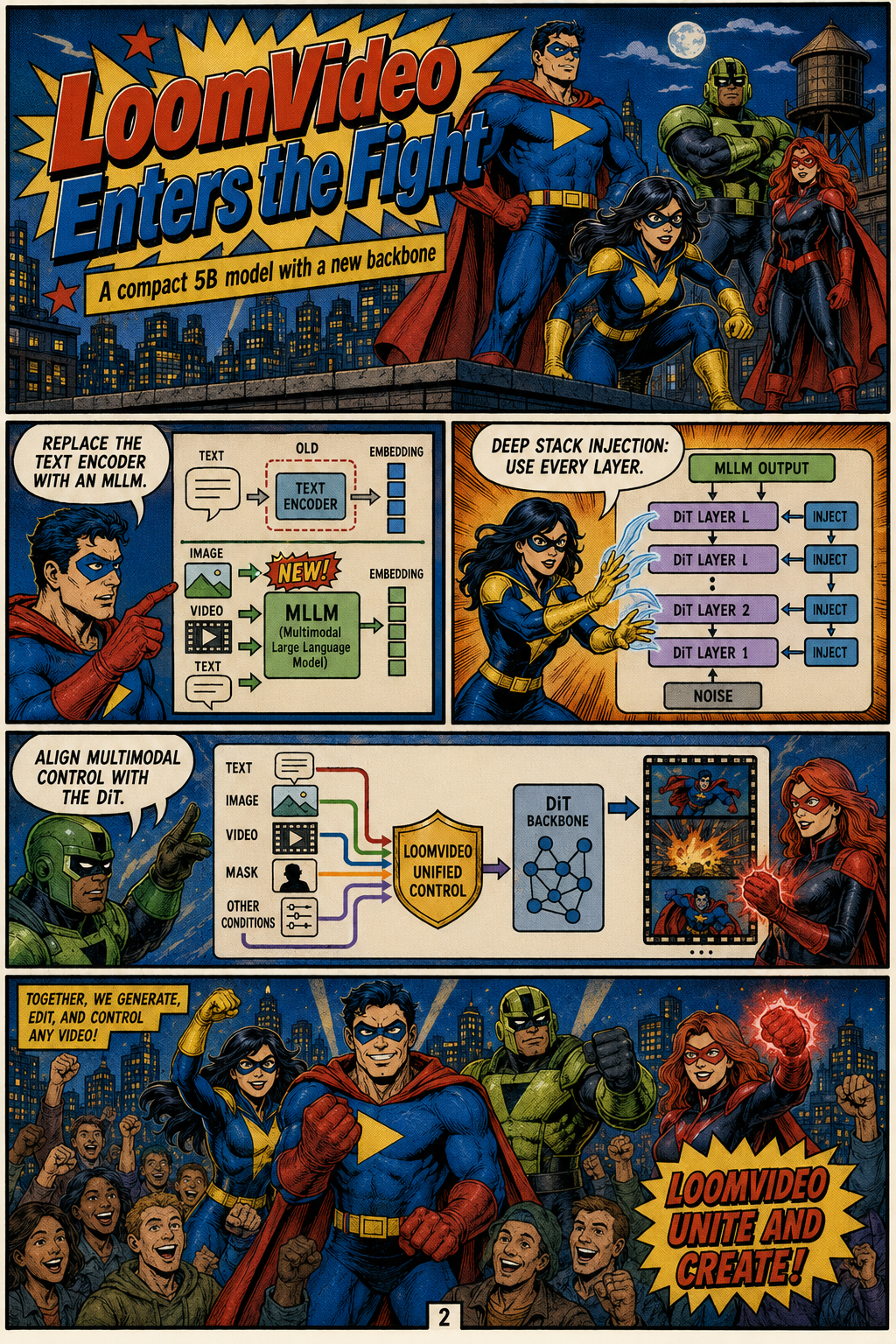
LoomVideo Enters the Fight
LoomVideo is built as a 5B-parameter unified architecture based on the Wan 2.2 Text-Image-to-Video model, but it replaces the standard T5 text encoder with Qwen3-VL, a Multimodal Large Language Model. This substitution allows the system to process interleaved multimodal inputs rather than treating text as the only high-level control signal. The paper’s Deepstack injection mechanism extracts hidden-state features from every layer of Qwen3-VL and injects them into corresponding layers of the Diffusion Transformer through cross-attention. This design contrasts with approaches that use only the final-layer embedding of a vision-language model, which may discard useful intermediate semantic and visual information. By aligning multi-layer MLLM representations with the DiT denoising process, LoomVideo aims to connect fine-grained instructions, reference images, and video priors more tightly. The implication is that model capacity can be used more efficiently by improving conditioning structure rather than simply scaling parameter count.
The Zero-Overhead Editing Move
The paper’s key efficiency mechanism for editing is Scale-and-Add conditioning, which replaces source-video token concatenation with latent-space addition. Instead of appending the clean source video as extra tokens, LoomVideo scales the clean source video latent according to the current diffusion timestep and directly adds it to the noised target latent. This introduces zero additional sequence tokens, so the Diffusion Transformer avoids the attention-cost increase caused by longer concatenated sequences. The authors emphasize that this lightweight conditioning still supports complex, non-rigid editing operations, including changes to human actions, clothing, camera angles, and visual style. The method is designed to preserve the benefits of source-video guidance while making unified editing substantially more practical. In the paper’s broader argument, Scale-and-Add is the mechanism that turns a compact unified model into an efficient alternative to much heavier concatenation-based systems.

Multiple References, Still in Formation
For reference-image-guided generation and editing, LoomVideo introduces a Negative Temporal RoPE strategy to distinguish static reference images from temporal video frames. Rotary positional encoding normally helps a video model represent frame order, but multiple reference images can confuse this structure if they are placed into the same temporal indexing scheme as generated frames. The paper assigns negative temporal indices to reference images so they can provide identity, clothing, background, object, or style guidance without being treated as ordinary video frames. This mechanism is intended to preserve the temporal dynamics of the generated video while still allowing several references to condition the output. The method directly supports the paper’s focus on interleaved multimodal prompts, where different images may specify different entities or attributes. By separating references from the video timeline, LoomVideo can use multi-image guidance without disrupting spatiotemporal consistency.

Proof in the City Lights
The training recipe in the paper is progressive, moving from semantic alignment to high-resolution task adaptation and then to complex reference-guided instruction following. Stage 1 trains low-resolution semantic alignment by extracting MLLM embeddings and injecting them into the Diffusion Transformer. Stage 2 scales to higher resolution and jointly trains fundamental image and video generation alongside reconstruction and editing tasks. Stage 3 incorporates diverse reference images and advanced text instructions, expanding the model’s ability to perform controllable multimodal generation and editing. The paper also reports reinforcement learning post-training to improve instruction following and generation fidelity. Across comprehensive benchmarks, LoomVideo is described as state-of-the-art or highly competitive, with especially strong performance in reference-image-guided editing and controllable e-commerce and fashion generation. Because the 5B architecture uses Scale-and-Add rather than token concatenation, the paper reports at least a 5.41× inference-speed acceleration over comparable unified models with similar capabilities.
