ReadPaper Blog
Latent Spatial Memory for Video World Models
The paper introduces latent spatial memory, a 3D cache for video world models that stores diffusion latent tokens at world-space locations instead of storing RGB-colored point clouds. Its method, Mirage, addresses geometric drift in camera-controllable video generation by using depth-guided back-projection, latent-resolution readout, and iterative memory updates, achieving stronger long-horizon spatial consistency while reducing generation time and GPU memory use.
Source: Latent Spatial Memory for Video World Models

A Room Full of Tiny Pictures
The paper targets a central weakness of video world models: they can synthesize visually plausible frames while failing to preserve a stable 3D scene as the camera moves over long trajectories. The authors argue that large-scale video diffusion models, including latent-space video generators and Diffusion Transformer-style systems, often treat generation as a primarily two-dimensional sequence problem. This leads to geometric drift, parallax violations, and inconsistent scene structure when the camera revisits previously observed regions. The paper frames this as a limitation of short-context autoregressive generation, where earlier spatial evidence fades as new chunks are produced. Its motivation is to give a video world model a persistent spatial representation so that generated frames remain anchored to a shared world coordinate system.
The Old Trick Is Too Slow
The paper explains that prior spatial-memory systems often solve consistency by building an explicit RGB point cloud from observed or generated frames. In that design, a frame is depth-lifted into colored 3D points, the accumulated point cloud is rasterized from each new target camera pose, and the rendered RGB image is then encoded again through the VAE to become a conditioning latent. The authors identify this rasterize-and-encode loop as both computationally expensive and representationally lossy. It is expensive because rendering millions of colored points and running pixel-resolution VAE encoding can dominate wall-clock time, especially as the cache grows. It is lossy because the conditioning signal must detour through RGB reconstruction, where VAE artifacts, visibility holes, rasterization errors, and distribution mismatch can degrade the latent features consumed by the diffusion backbone.

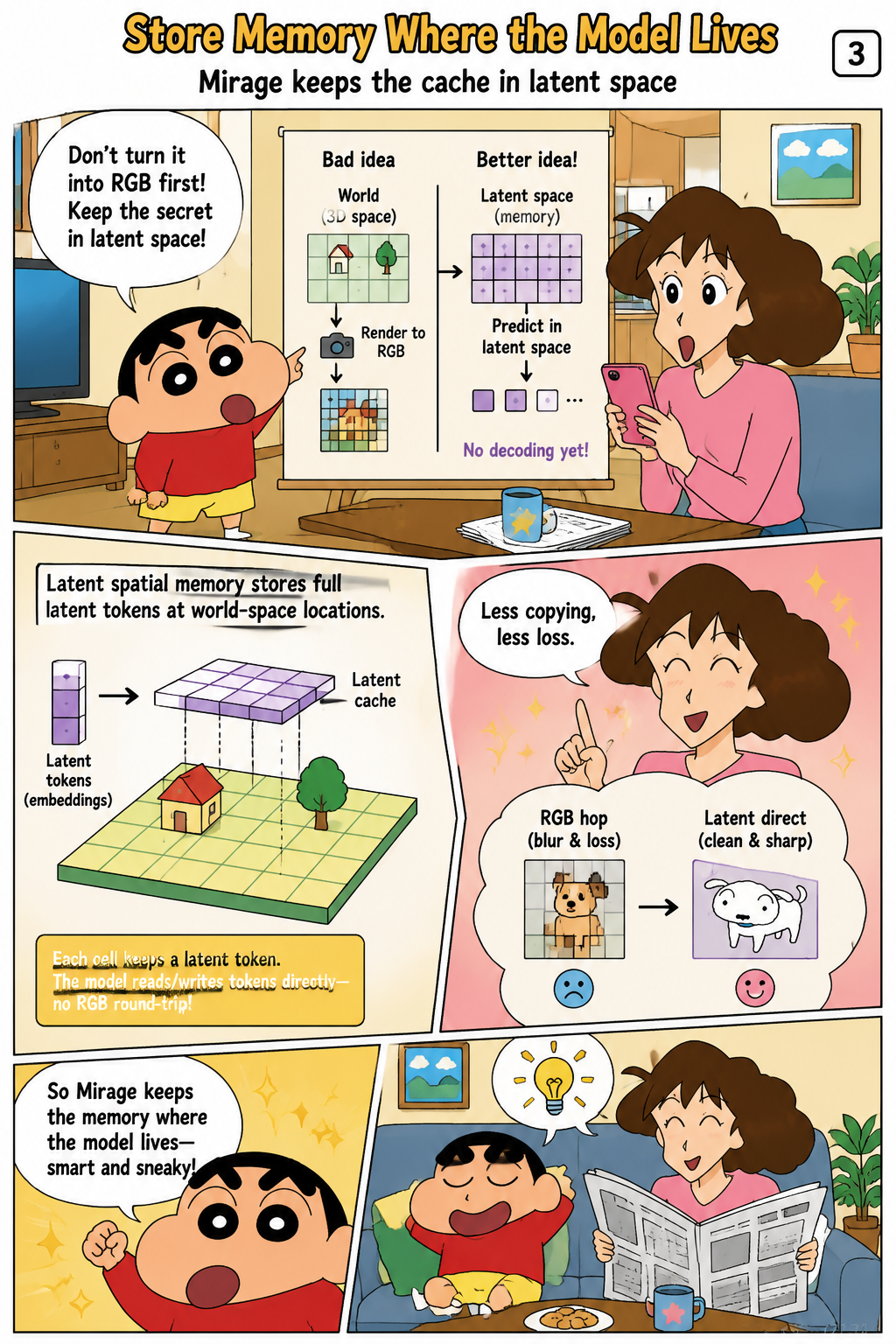
Store Memory Where the Model Lives
The paper’s main contribution is latent spatial memory, a persistent 3D cache that stores the diffusion model’s native latent features rather than RGB colors. In this formulation, an input image is encoded into a VAE latent tensor, and each latent-grid cell is lifted into 3D using depth-guided back-projection. Each memory element therefore pairs a world-space coordinate with a full-channel latent token, preserving information in the representation where the denoising model actually operates. At readout time, the cache is projected directly onto the target camera grid at latent resolution with depth-aware visibility handling. This design avoids pixel-space reconstruction, eliminates per-step VAE encoding of rendered memory, and reduces cache cost by exploiting the spatial compression already provided by the VAE latent space.
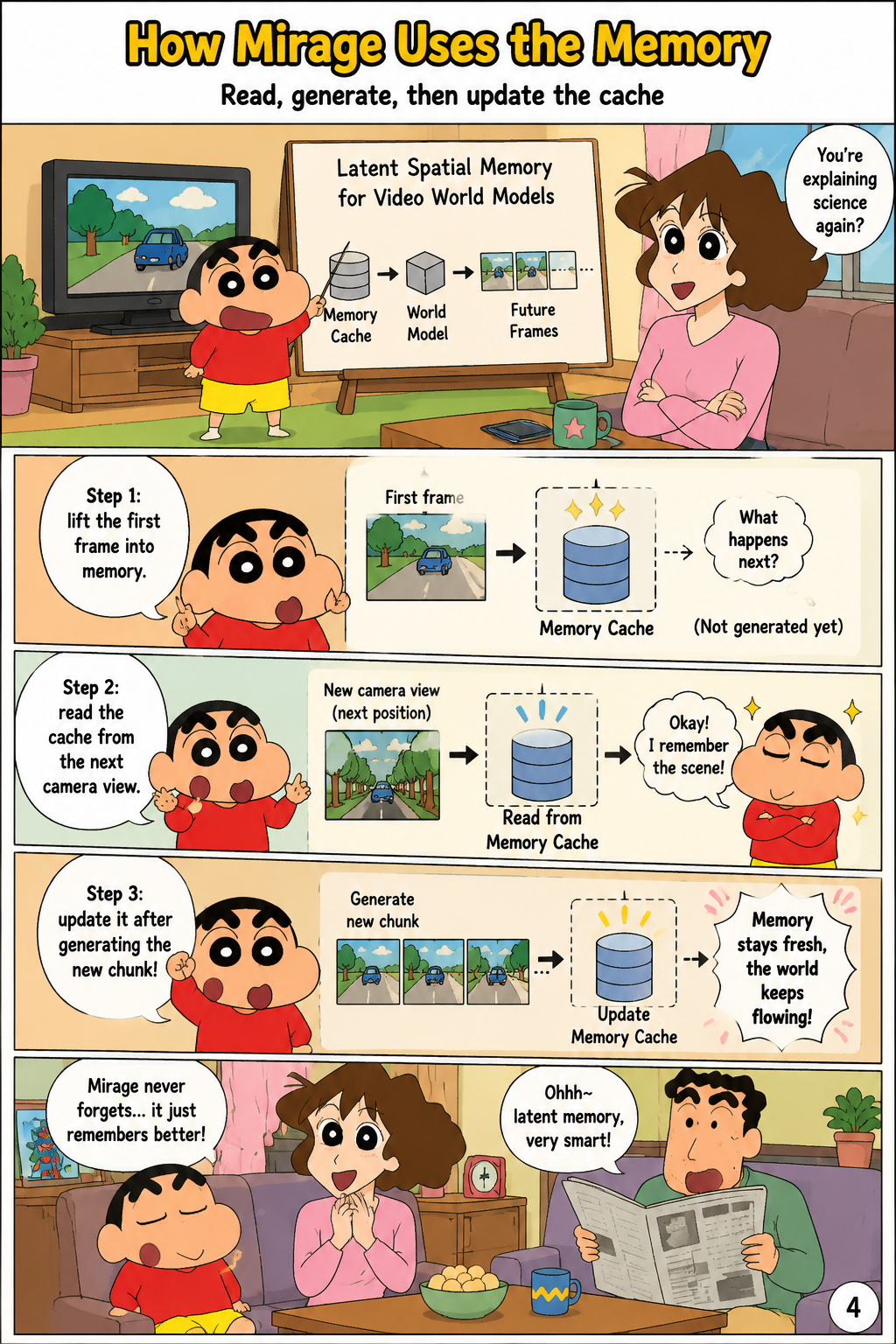
How Mirage Uses the Memory
The paper builds the representation into Mirage, a video world model organized around an initialize-readout-update cycle for long-horizon generation. Mirage initializes memory from the first frame by encoding it with the VAE and lifting latent tokens into a 3D cache through estimated depth. For each subsequent chunk, Mirage reads the latent spatial memory by projecting cached tokens into every target camera pose, producing target-view latent tensors that condition the diffusion backbone through a ControlNet-style side branch. After denoising and decoding the output frames, Mirage updates the cache by estimating depth, segmenting dynamic objects, re-encoding generated frames into clean latent features, and back-projecting the resulting tokens into memory. This repeated cycle lets the model generate extended camera trajectories while retaining access to earlier scene evidence beyond the limited temporal window of the video diffusion backbone.
What the Paper Claims
The paper evaluates Mirage on WorldScore and RealEstate10K to test both world-generation quality and reconstruction behavior under camera motion. The reported results show state-of-the-art performance on WorldScore and strong reconstruction quality on RealEstate10K, indicating that latent spatial memory can improve spatially consistent generation without sacrificing visual fidelity. The paper also reports efficiency gains of up to 10.57× faster end-to-end video generation and up to 55× lower GPU memory usage for the 3D cache compared with RGB point-cloud memory baselines. These improvements follow directly from replacing full-resolution RGB rendering and VAE re-encoding with a single latent-resolution projection. The broader implication is that persistent 3D memory can be made practical for long camera trajectories when it is aligned with the latent representation used by modern diffusion video models.
