ReadPaper Blog
Decentralized Instruction Tuning: Conflict-Aware Splitting and Weight Merging
The paper addresses a practical bottleneck in large-scale instruction tuning: heterogeneous task mixtures create gradient interference, while centralized training requires expensive cross-node synchronization. It proposes MERIT, a decentralized pipeline that splits datasets by measured gradient conflict, fine-tunes each partition independently, and merges the resulting models once through token-weighted parameter averaging. The result matters because MERIT improves or matches centralized joint training on multimodal and text-only instruction-tuning settings while reducing the need for tightly coupled compute infrastructure.
Source: Decentralized Instruction Tuning: Conflict-Aware Splitting and Weight Merging
Why Training Stalls
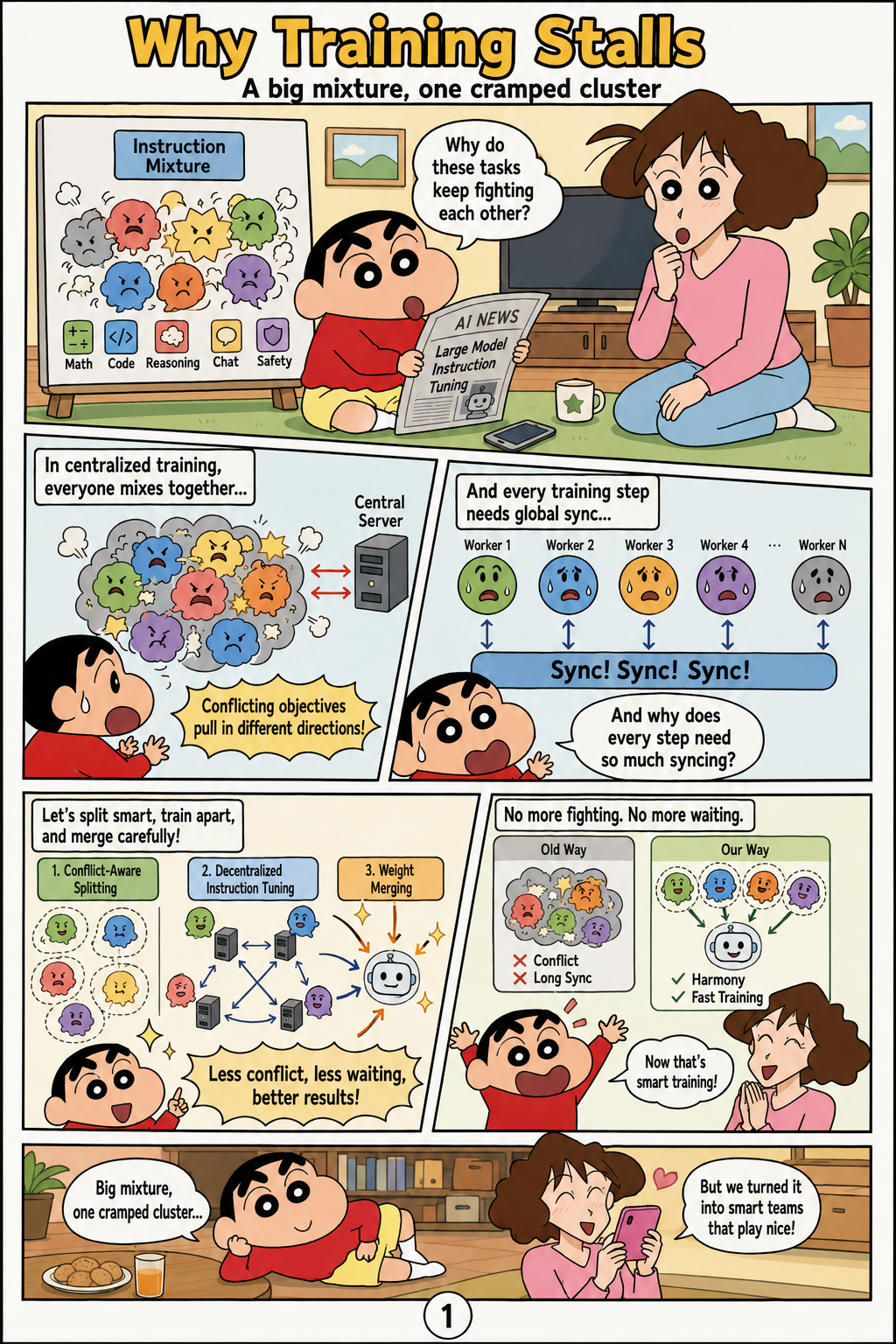
The paper starts from the observation that modern instruction tuning, especially for multimodal large language models, depends on increasingly heterogeneous mixtures of perception, reasoning, OCR, document-understanding, diagram-comprehension, and safety data. In such mixtures, the authors argue that centralized joint training suffers from gradient interference, where different datasets push the model parameters in conflicting directions and can cause negative transfer or stiff optimization dynamics. The systems problem is coupled to the optimization problem because joint training typically requires frequent gradient synchronization, such as all-reduce, across GPU servers. This makes the standard recipe difficult to use in fragmented compute environments, including heterogeneous GPU pools, geo-distributed clusters, and cloud spot instances. The paper frames its central question as whether independent training on carefully chosen parts of the mixture can reduce interference and then be reconciled in weight space without costly synchronization.
The Gap
The paper identifies a gap between the scale of today’s instruction mixtures and the assumptions behind conventional multi-task training methods. Classical gradient-surgery or task-wise correction methods can mitigate gradient conflicts in smaller settings, but the authors argue that they become infeasible for more than a hundred tasks and billion-parameter models because they require fine-grained gradient information and coordination. As a result, practitioners often rely on mixture-ratio curation, which is coarse and does not directly solve dataset-level interference. The paper also emphasizes that centralized joint training assumes a tightly coupled cluster with high-bandwidth interconnects, an assumption that breaks when compute is distributed, heterogeneous, or intermittently available. This motivates a decentralized alternative in which synchronization is avoided during fine-tuning rather than merely optimized.

Core Idea
The proposed method, MERIT, turns the instruction-tuning mixture into merge-ready partitions before training begins. It estimates dataset-level gradient conflicts using a calibration set, then applies PCA-aligned conflict splitting so that datasets are partitioned along the dominant axes of disagreement. Each partition is fine-tuned independently from the same initialization, with no communication between partitions during training. After fine-tuning, the resulting models are merged once in parameter space using token-weighted averaging. The method relies on the idea of a merge-ready initialization, where fine-tuned models that start from the same strong checkpoint remain within a shared flat basin and can therefore be averaged without leaving a low-loss region.

Why It Works
The theoretical contribution of the paper is a local quadratic analysis of weight merging inside a shared flat basin. Under this view, averaging independently fine-tuned weights produces a curvature-weighted variance reduction, meaning that disagreement among models is suppressed in directions where the loss surface is sensitive. The analysis further argues that PCA-aligned conflict splitting maximizes the benefit of merging along high-curvature directions because the partitions are chosen to expose and separate the major conflict modes. The authors also interpret merging as a form of spectral filtering, where averaging attenuates unstable or high-variance components in parameter updates. This gives MERIT a theoretical rationale beyond communication savings: the final merge can act as implicit norm regularization while preserving useful task-specific learning from the separate fine-tuning runs.

Takeaway
Empirically, the paper evaluates MERIT on Qwen2.5-VL-3B with 136 Vision-FLAN tasks and reports an improvement in the 8-benchmark average from 54.3 under centralized joint training to 57.0 with the decentralized merge-ready pipeline. The same recipe is reported to scale to a 7B model trained on a 1.6M-example, 176-source mixture, where it matches or exceeds centralized joint training with minimal cost overhead. The authors also report transfer to text-only FLAN, suggesting that the approach is not limited to vision-language instruction tuning. These results support the paper’s broader implication that dataset conflict structure can be used as a systems-aware training signal. MERIT therefore reframes large-scale instruction tuning as a problem of conflict-aware partitioning plus one-shot weight-space reconciliation, rather than as a single synchronized optimization trajectory.
